前言
众所周知,python在爬虫领域有着得天独厚的优势,今天,我们来用python爬取王者荣耀英雄皮肤图片。
本章中,我会着重带大家了解爬取网页的基本流程。
网页分析
首先,咱去王者荣耀的官网瞧瞧:王者荣耀官方网站-腾讯游戏 (建议用谷歌浏览器),我们的目标是,找到英雄皮肤的url地址,如下图,官网是这样的:
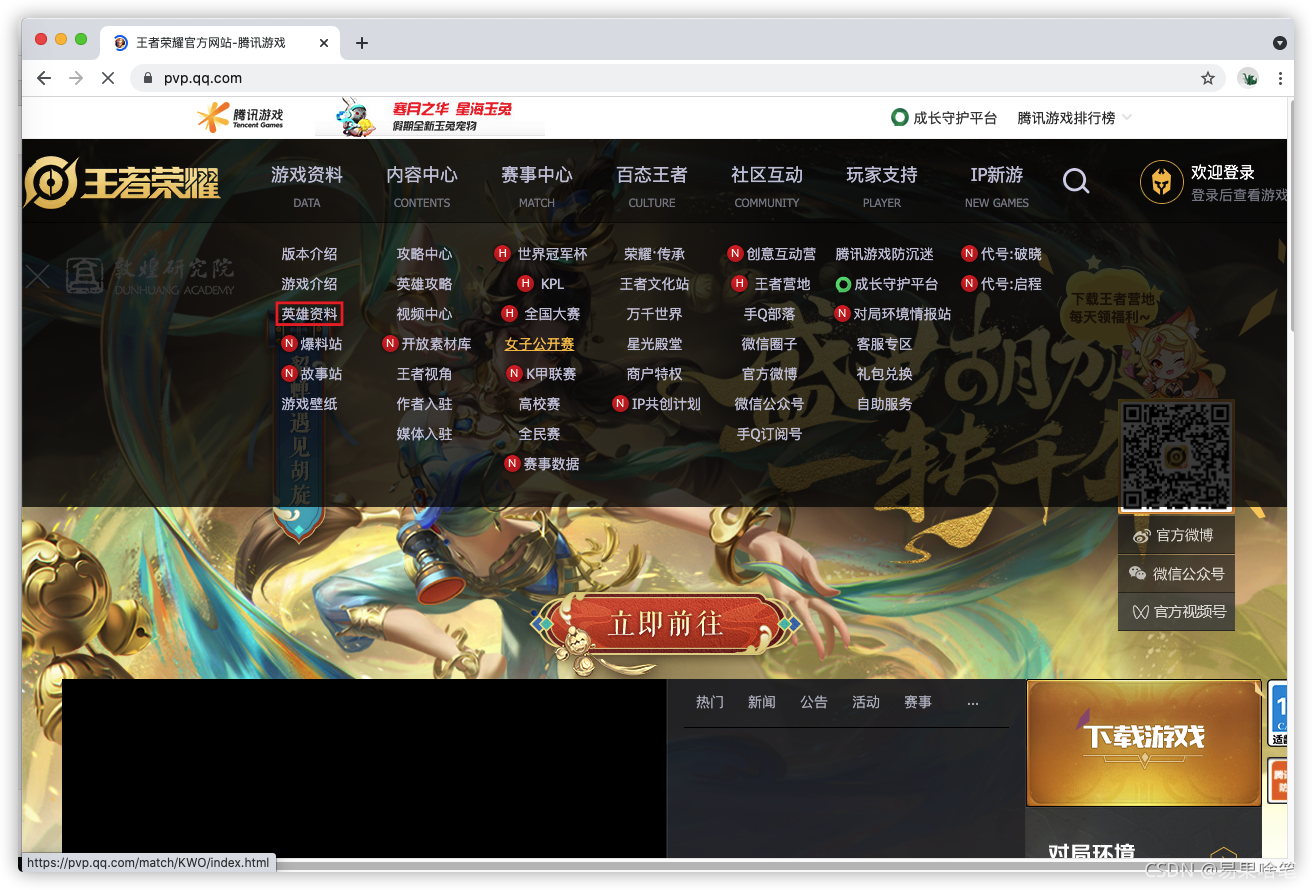
发现图中的红框部分-----英雄资料,点进去看看:
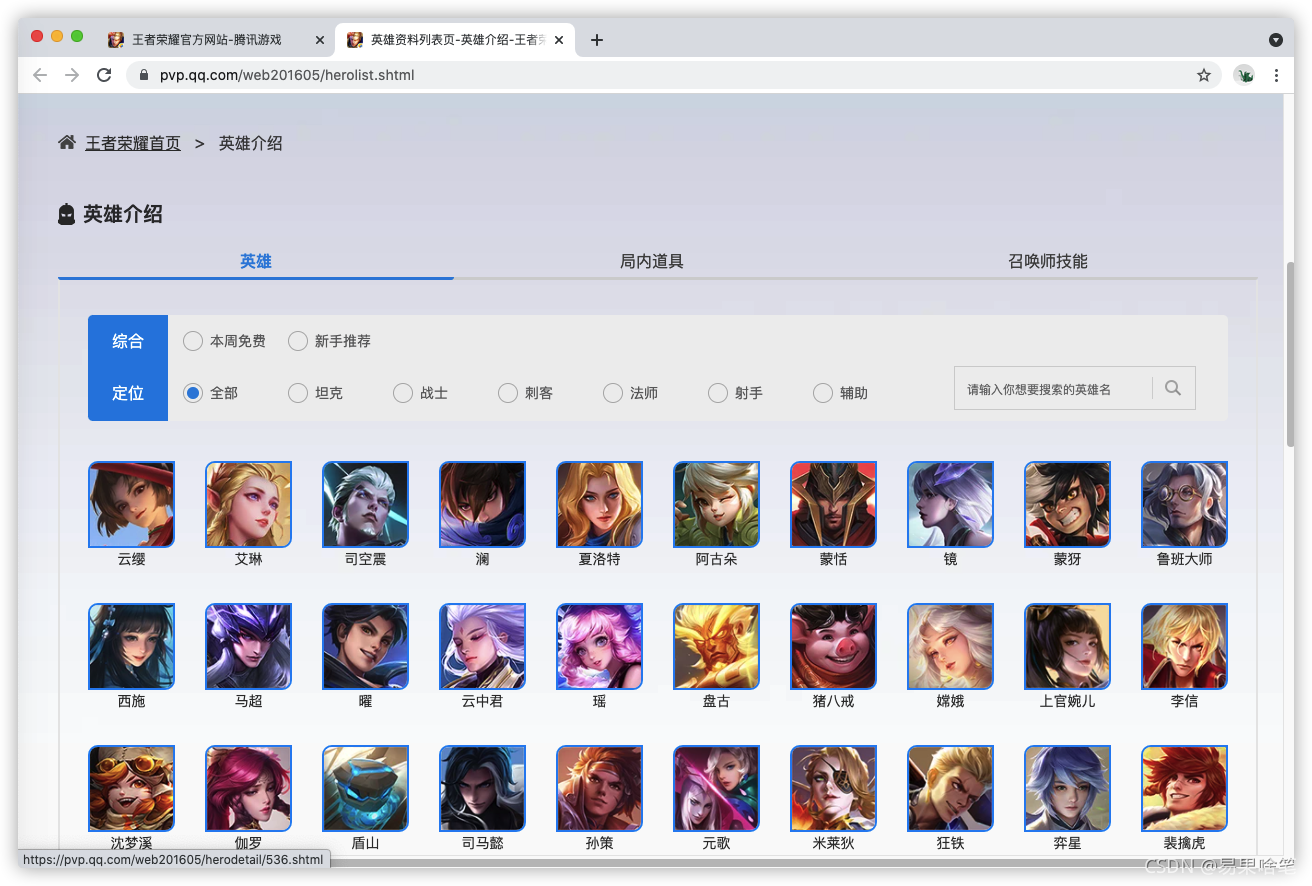
往下滑,我们可以发现好多的英雄头像,点一个进去看看,比如貂蝉姐姐:
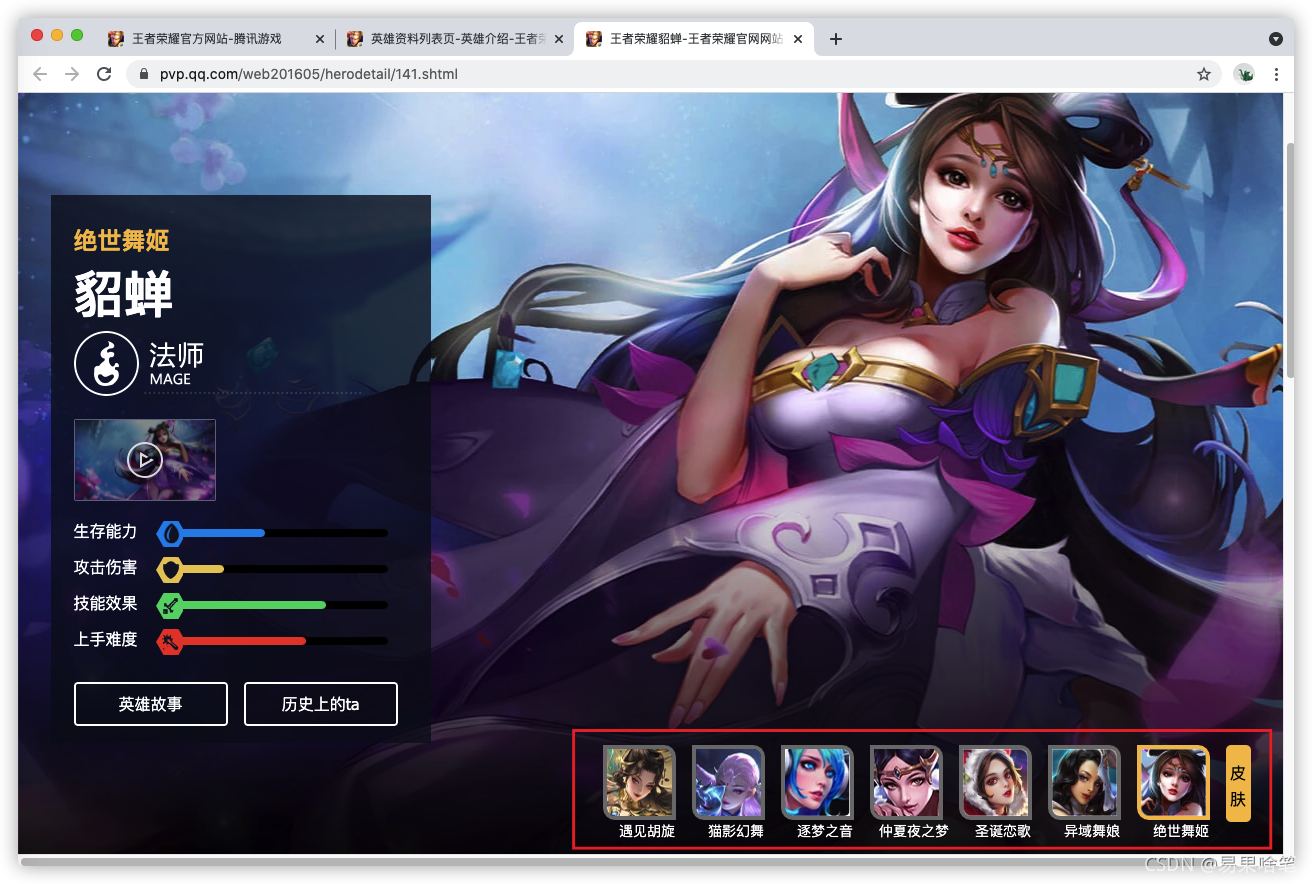
如上图,我们看到了貂蝉的所有皮肤, 现在我们要找到这些皮肤的url地址,鼠标放至皮肤图片处,在谷歌浏览器中,按F12调出开发者工具,可以看到如下内容:
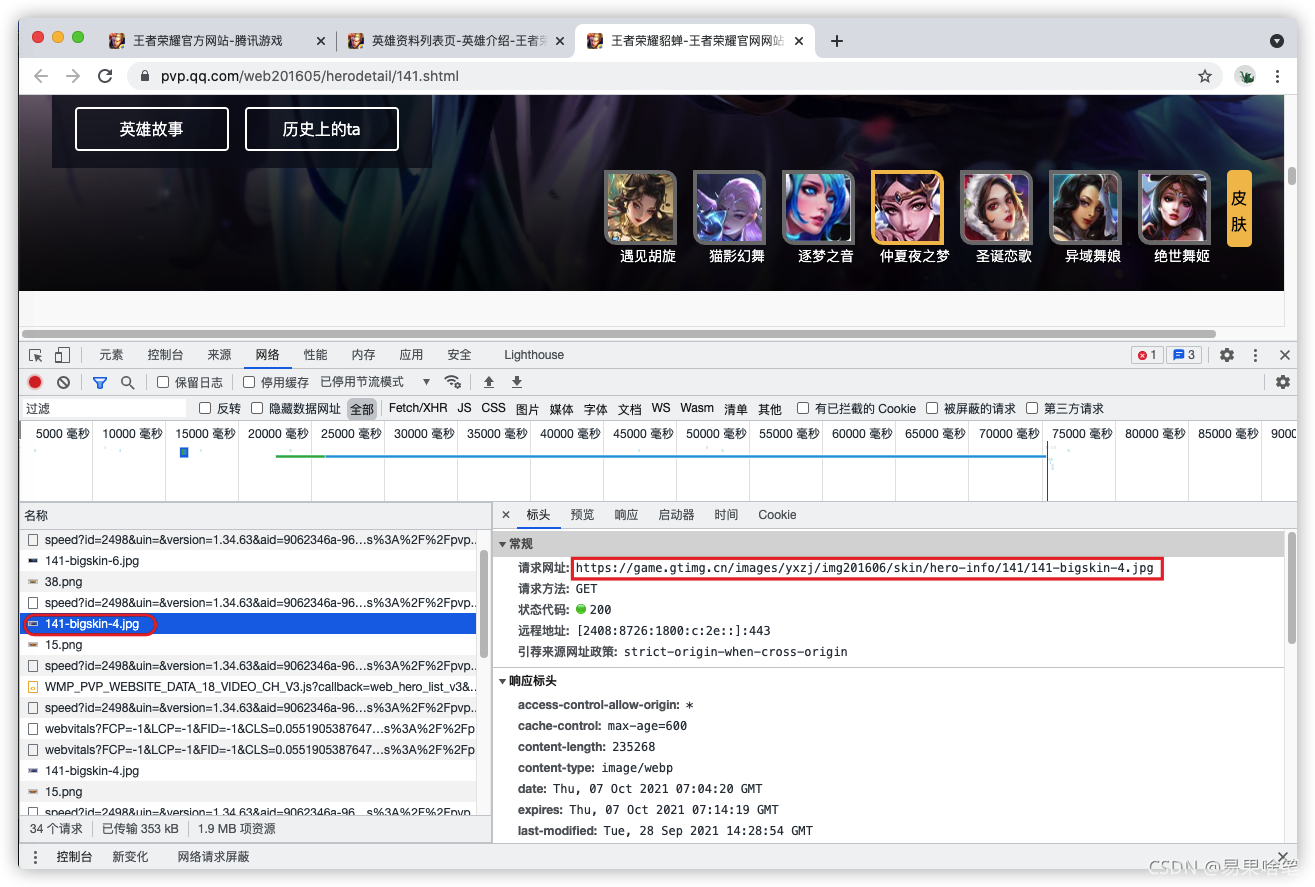
我们找到了这个皮肤的url地址:
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/141/141-bigskin-7.jpg
再换一个皮肤试试:
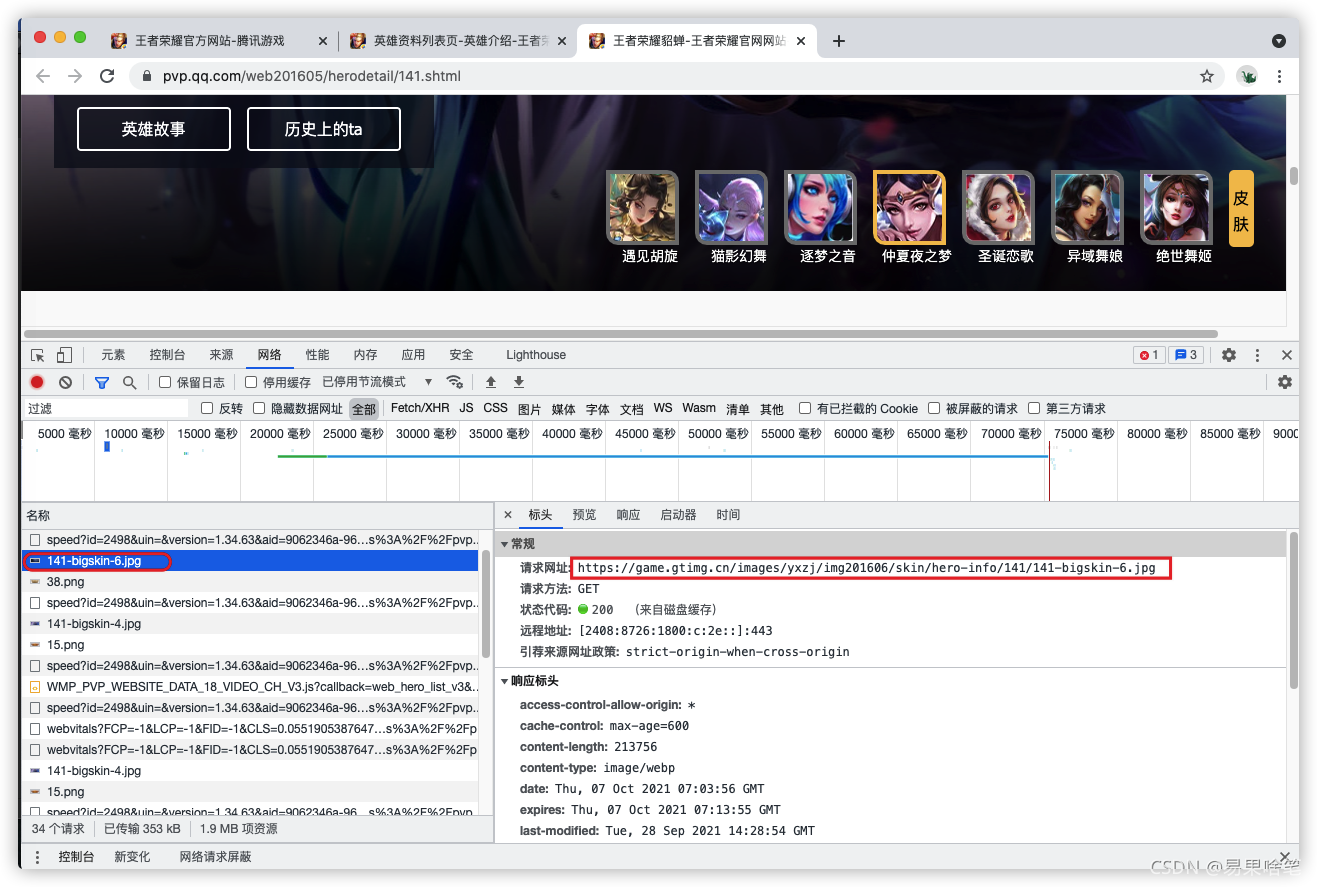
她的url地址为:
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/141/141-bigskin-6.jpg
探索url地址的规律
对比这两张皮肤图片的url地址:
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/141/141-bigskin-7.jpg
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/141/141-bigskin-6.jpg
我们发现,这两个url地址,仅仅是最后一个数字不同,我们猜测,这个数字应该是不同皮肤的某种编号。
接着,我们继续看看其他英雄的皮肤图片,如百里守约,同貂蝉的一样,我们找到了百里的几个皮肤的url地址如下:
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/196/196-bigskin-2.jpg
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/196/196-bigskin-3.jpg
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/196/196-bigskin-4.jpg
从这三个url地址可以发现,百里的皮肤url地址,也仅仅最后一个数字不同, 同样,我们猜测这应该代表着百里不同皮肤的编号。
接着,我们对比一下貂蝉和百里的皮肤url地址有何不同:
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/141/141-bigskin-6.jpg
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/196/196-bigskin-2.jpg
我们发现,两个英雄皮肤除了编号(最后一个数字)不同,最大的不同是 /hero-info/ 后面的整数,貂蝉的是141,而百里的是196,据此猜测,这个整数应该是代表的是英雄的编号,至此,我们猜测,所有英雄皮肤的url地址的命名路径应该长下面这个样子:
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{英雄编号}/{英雄编号}-bigskin-{皮肤编号}.jpg
寻找所有英雄编号
地址找到了,现在的问题是,如何找到所有英雄的编号呢?
我们继续逛逛王者荣耀的官网,找找针对王者里的英雄还有哪些数据可以利用,几番寻找,我们发现了一个叫 herolist.json 的文件。地址为:
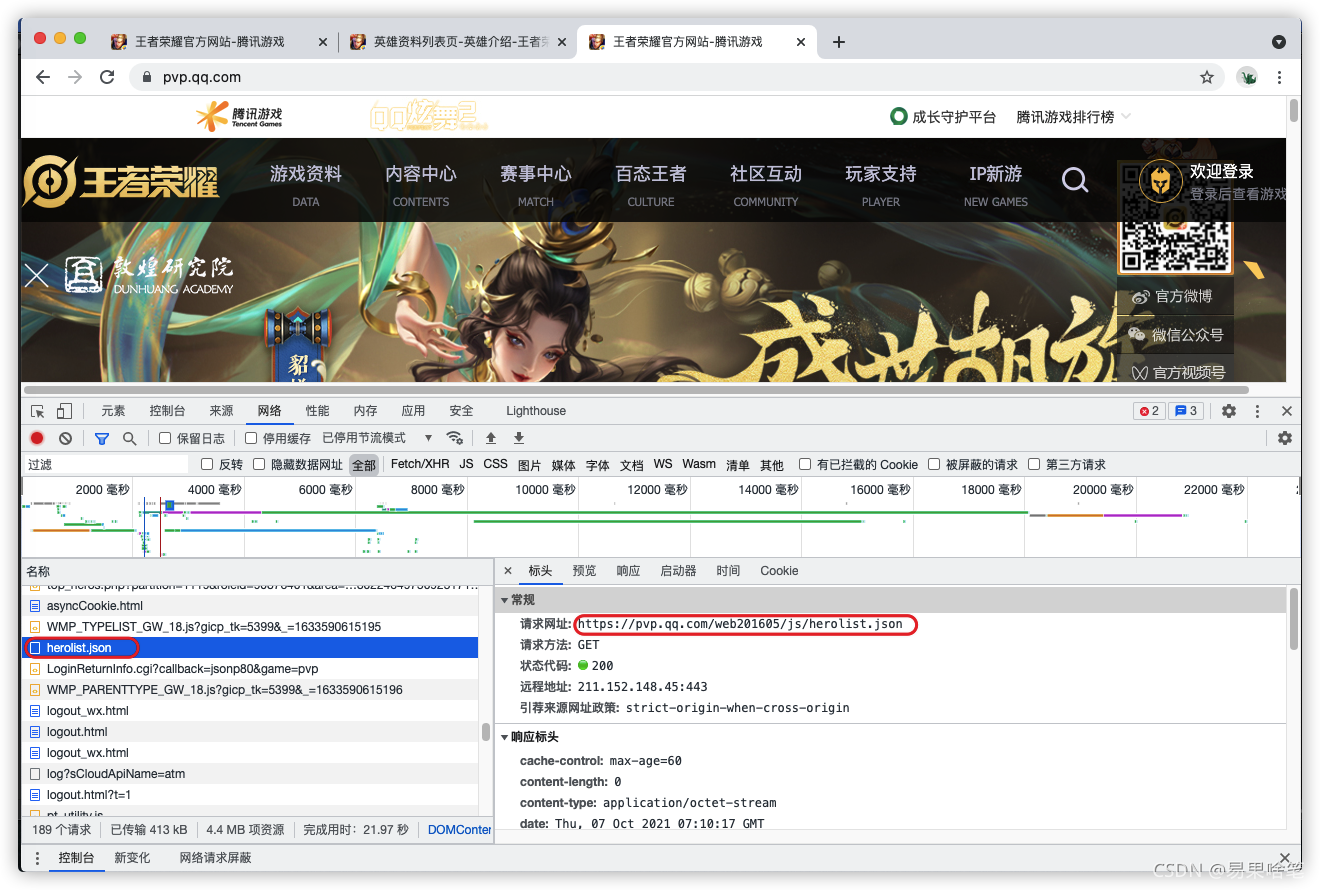
用浏览器打开这个json文件,神奇的事情发生了:
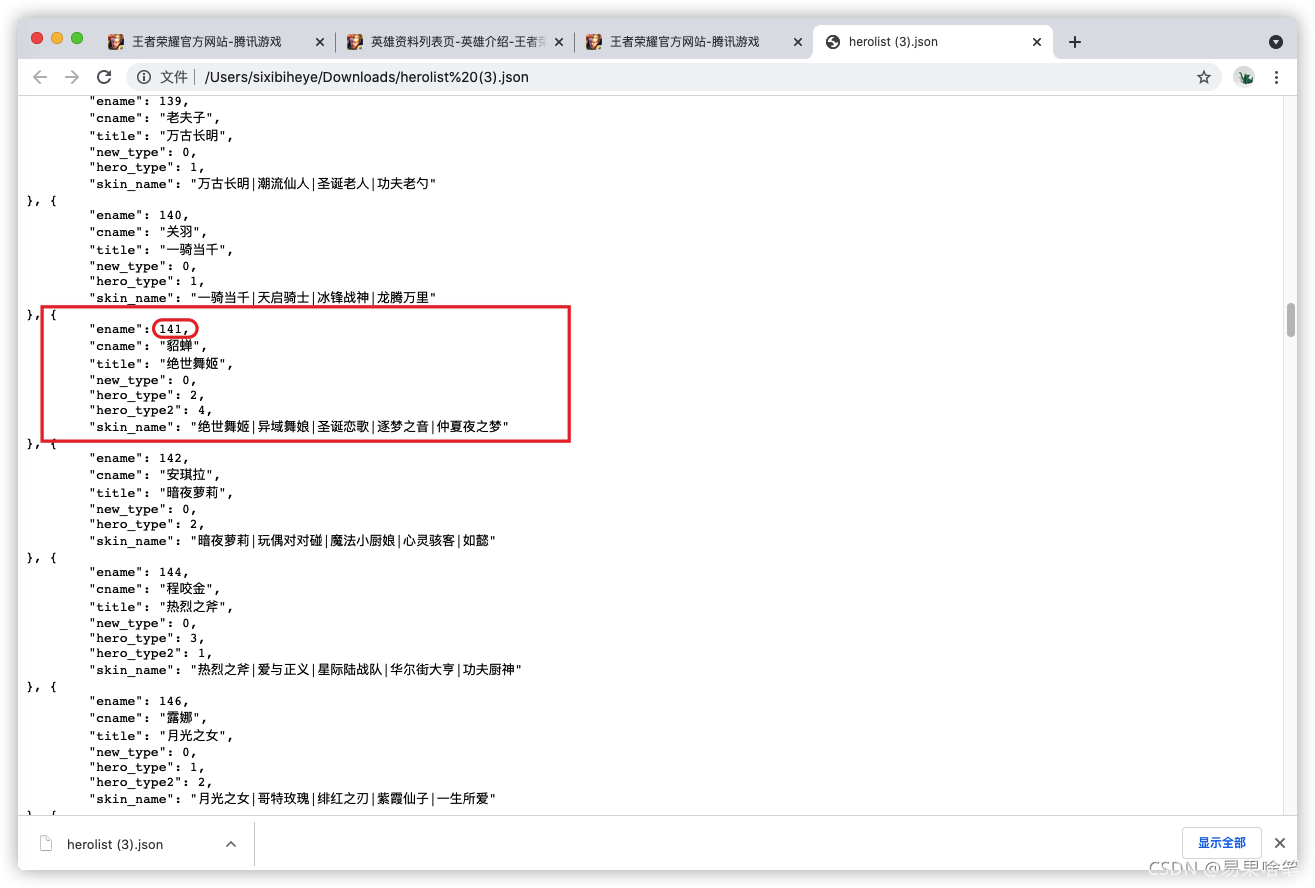
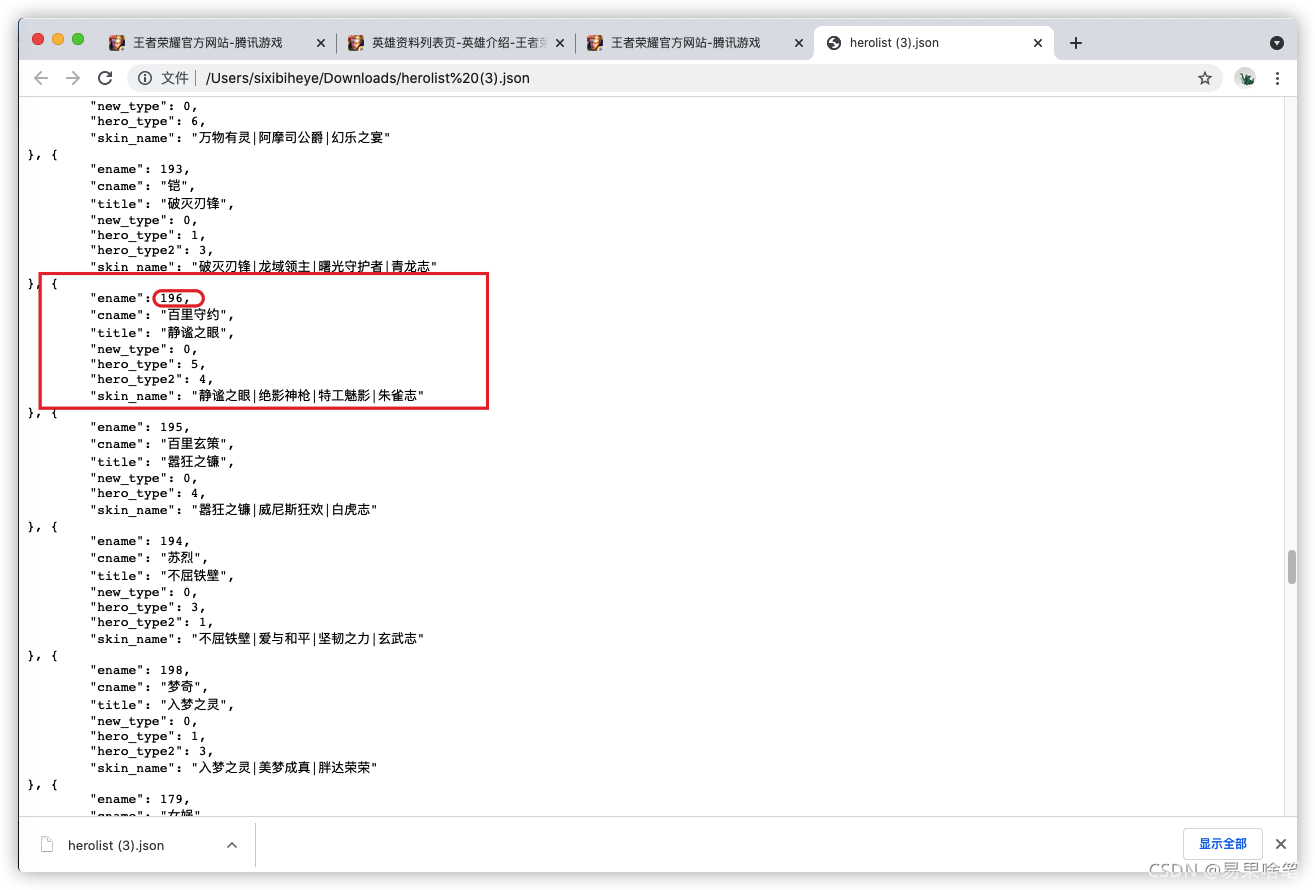
不知道大家对上图中貂蝉的“ename”属性的值“141”这个数据还有没有印象,没错!它不正是貂蝉的编号嘛!
上图中,百里的编号“196”也印证了我们的猜测。
编写代码
有了上述的分析,要爬取所有英雄的皮肤图片,就轻松多了。
在这,我们采用最基础的 requests 库来完成我们的爬取工作,代码如下:
1 | import requests |
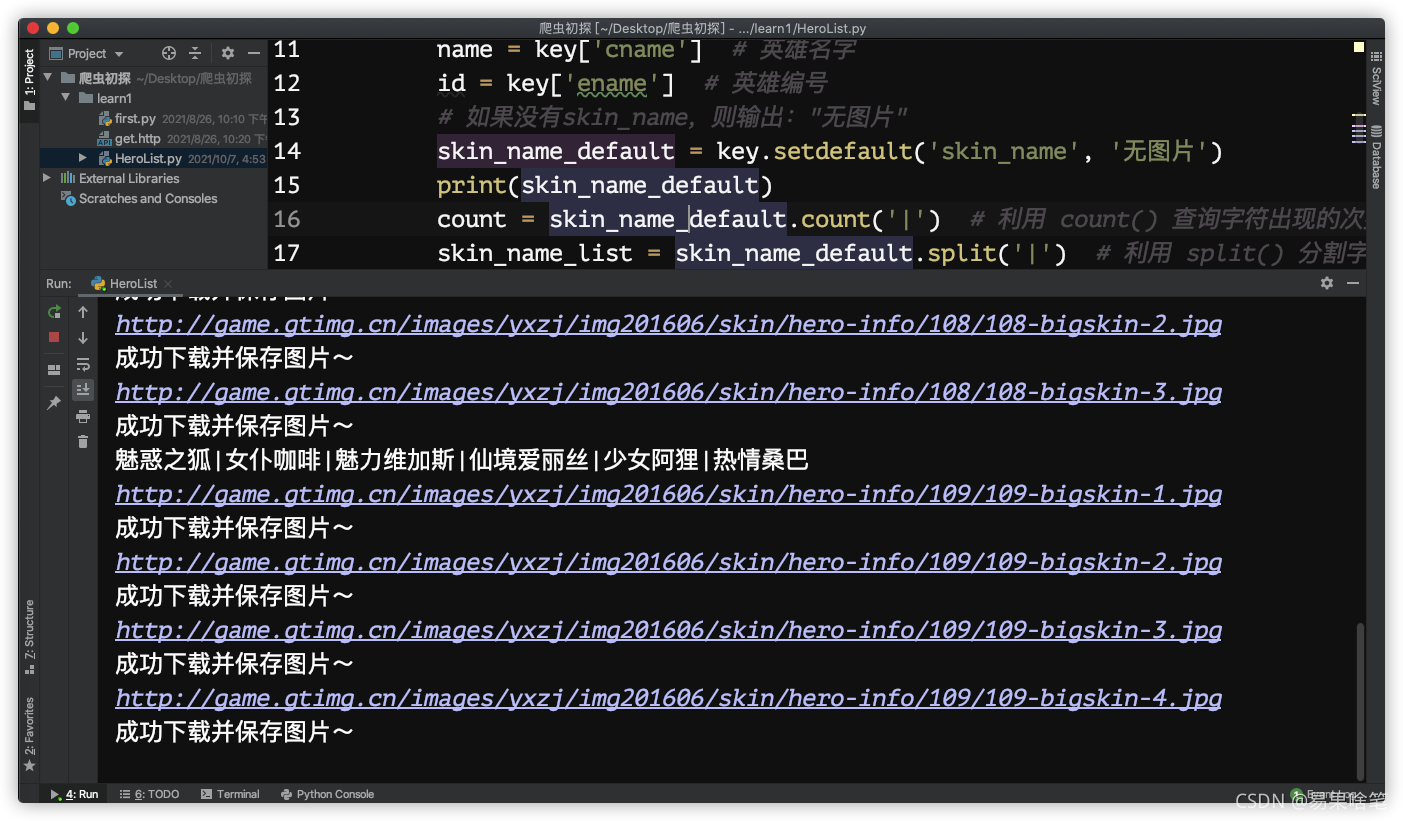
运行程序
点击运行,在控制台可以看到下载进度:
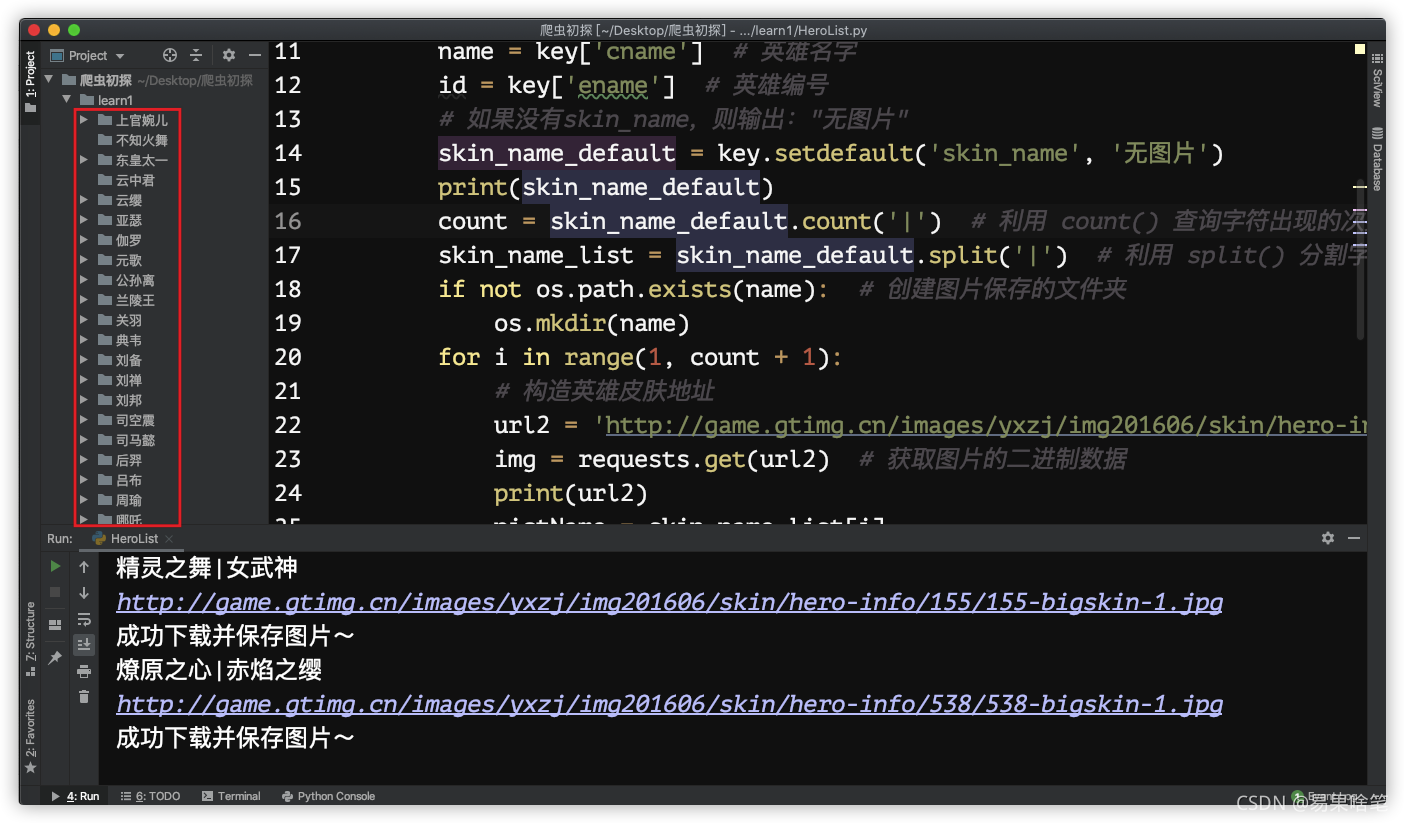
下载完成后,在当前目录下,我们能看到生成的英雄皮肤图片的文件夹:
下面,就让我们尽情的欣赏英雄们的图片吧~