
前言
趁着闲暇的时间,我们来系统学习一个python非常流行的框架-----Scrapy。Scrapy是一个使用python编写,基于Twisted框架的开源网络爬虫框架,目前由Scrapingphub Ltd维护。
Scrapy的最大特点,四个字:简单实用。
简单到什么程度,一天的学习即可掌握核心知识,并应用到实际中去。由于Scrapy灵活易扩展,开发社区活跃,跨平台支持,使得其使用群体广泛。
本着实用的原则,本教程不涉及Scrapy框架的底层实现讲解,对于一些不太好理解的地方,偶尔会涉及到Scrapy的底层原理,以便于理解。
安装Scrapy
安装Scrapy非常地简单,在任意操作系统下,均可以使用pip命令安装:
pip install scrapy
测试是否安装成功,可以在cmd(控制台)里输入scrapy:
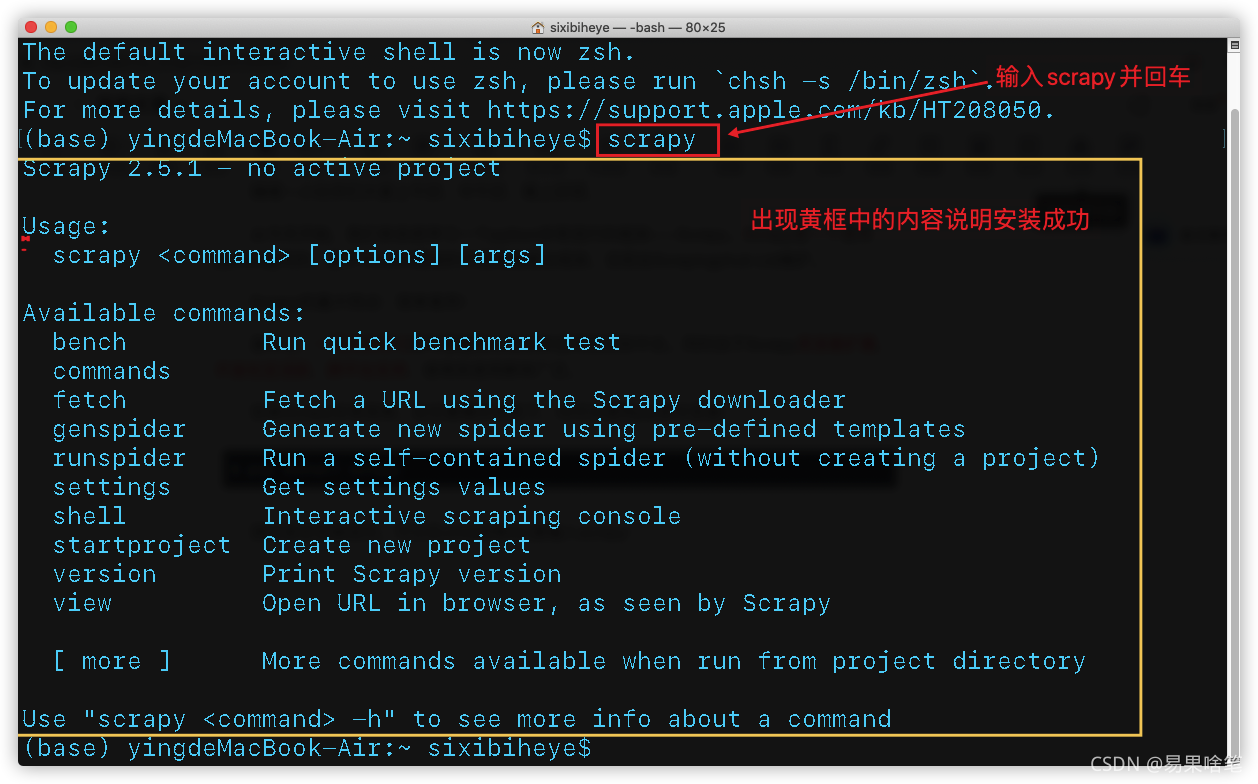
第一个Scrapy爬虫程序
下面我们来编写第一个Scrapy爬虫程序。
爬虫,首先得有“地”可爬。大家都听过,“爬虫学的好,牢饭少不了”,
我们不去爬取网站的私密信息,仅仅是为了学习和交流。
在这,有一个专供爬虫初学者训练爬虫技术的网站,网址为: All products | Books to Scrape - Sandbox
我们来瞧瞧这个网站的主界面:
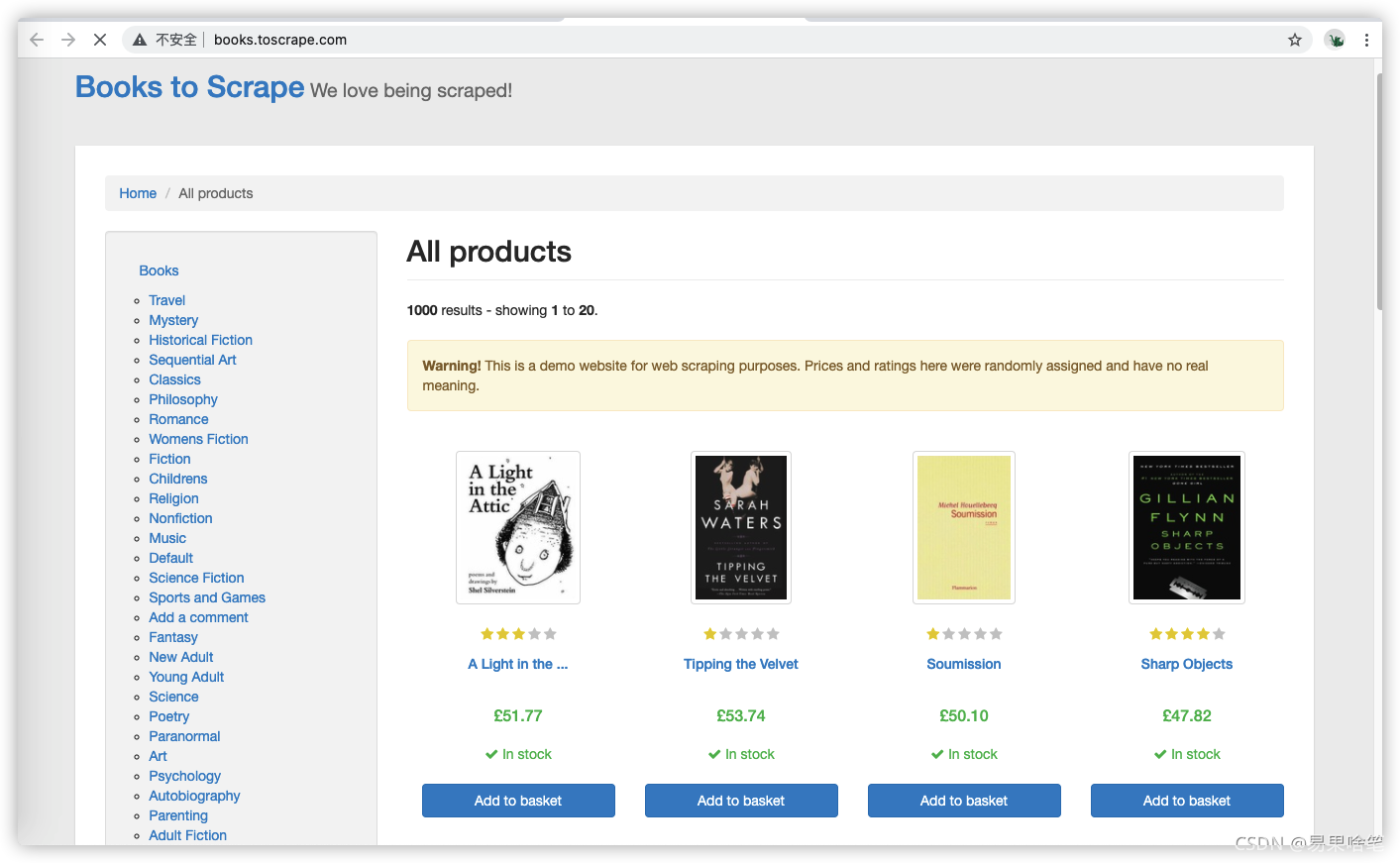
可以看到,里面有许多关于书籍的信息。
下面,我们就使用Scrapy框架来爬取这些书籍信息。咱分几步完成:
第一步:分析页面
编写爬虫程序前,我们首先要分析这个页面,这需要一点简单的html知识,现在主流的浏览器中都带有分析网站页面的工具或插件,个人比较推荐Chrome浏览器的开发者工具,因为它的功能实在是太强大了!
在Chrome浏览器中打开书籍信息所在的网页,接着按F12,即可调出谷歌的开发者工具,我们来看看这个网页的HTML源代码:
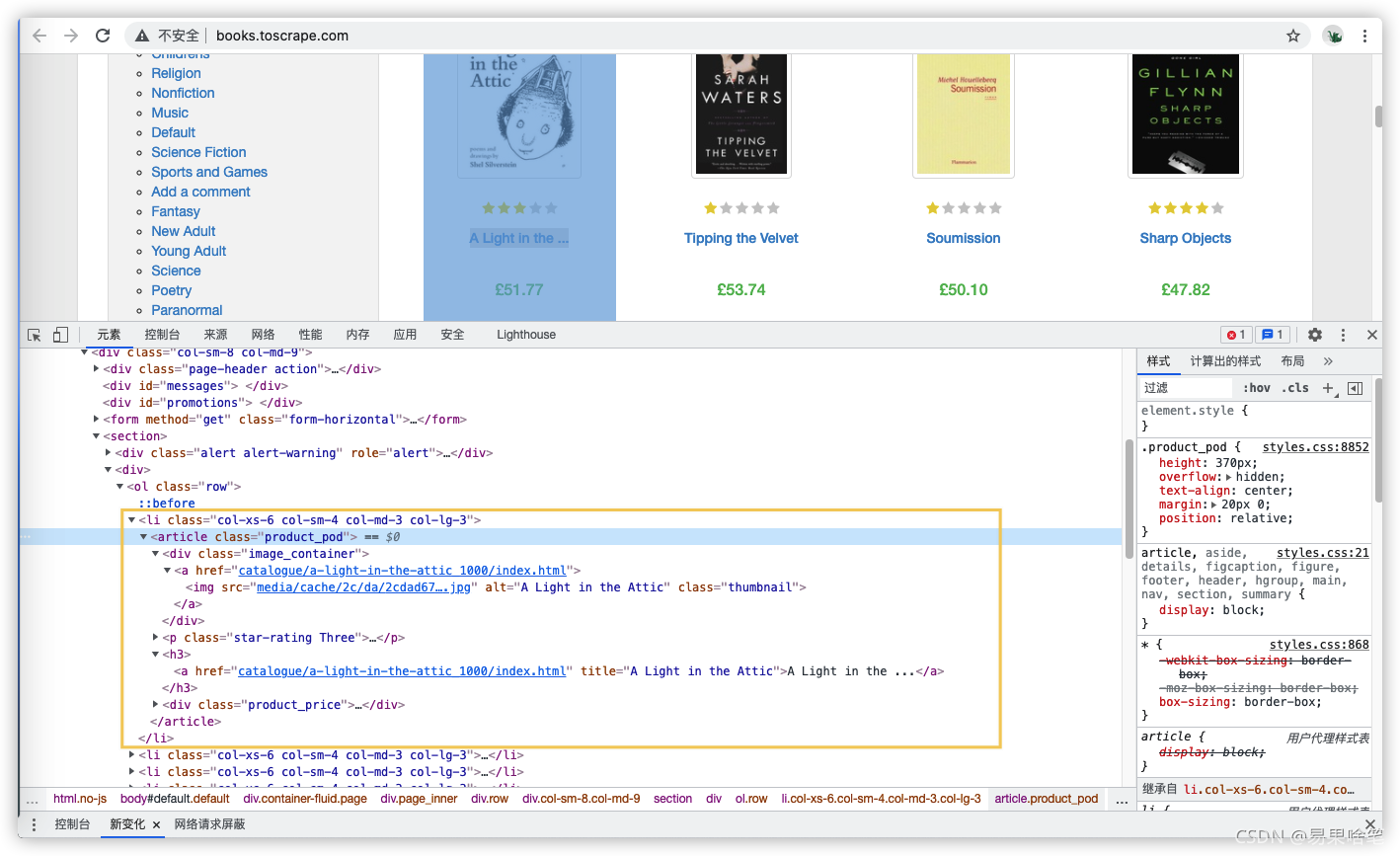
谷歌浏览器小技巧:如果你想找到页面某个内容所在的HTML代码,可以右键该内容,选择“审查元素”,即可定位到该内容所在的HTML代码。 (其他浏览器也有类似的方式)
从源代码中可以看到,所有的书籍信息放在了一个ol(无序标签)下, 其中的每一本书放在一个 li 块中,所有的书籍信息包裹在<article class="product_pod">元素中,具体信息有:
- 书名信息:其下
h3 > a元素的title属性中 - 书价信息:其下
<p class="price_color">元素的文本中
当然网页中书籍信息还有许多,此处我们先爬取这两个信息。
第二步:创建项目
同其他框架一样,使用Scrapy,首先得新建一个Scrapy项目,在cmd(控制台)中使用如下指令创建一个Scrapy项目:
scrapy startproject 项目名
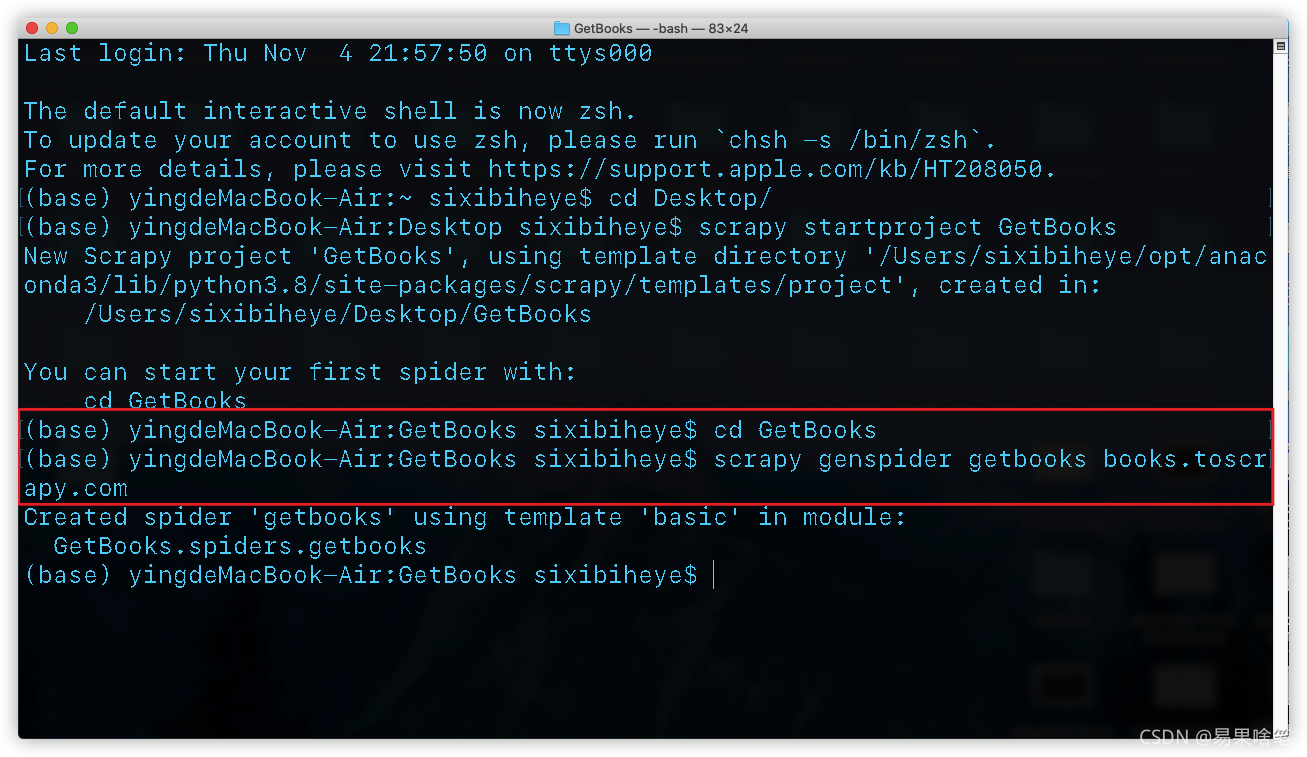
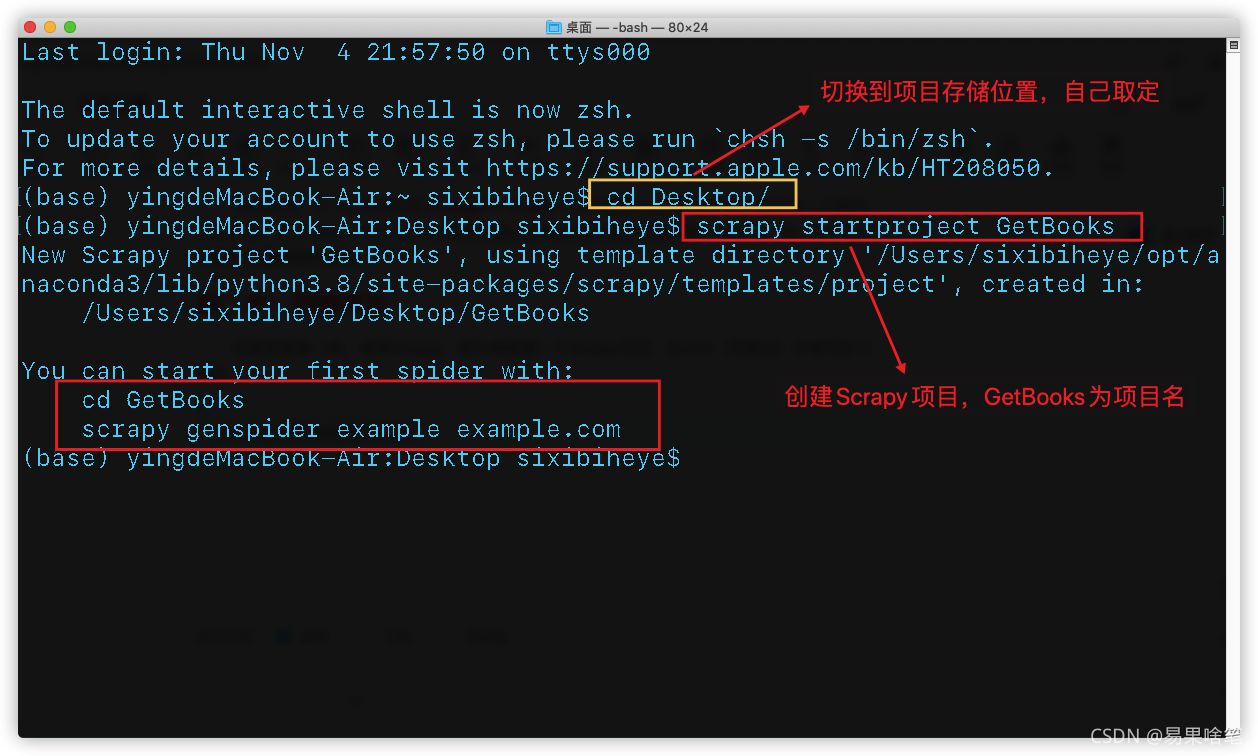 根据执行结果(红框所述),先
根据执行结果(红框所述),先cd到项目中,再执行如下命令:
scrapy genspider 爬虫名 待爬取的网站域名
 这样,在项目存储位置处,我们可以看到项目的文件结构:
这样,在项目存储位置处,我们可以看到项目的文件结构:
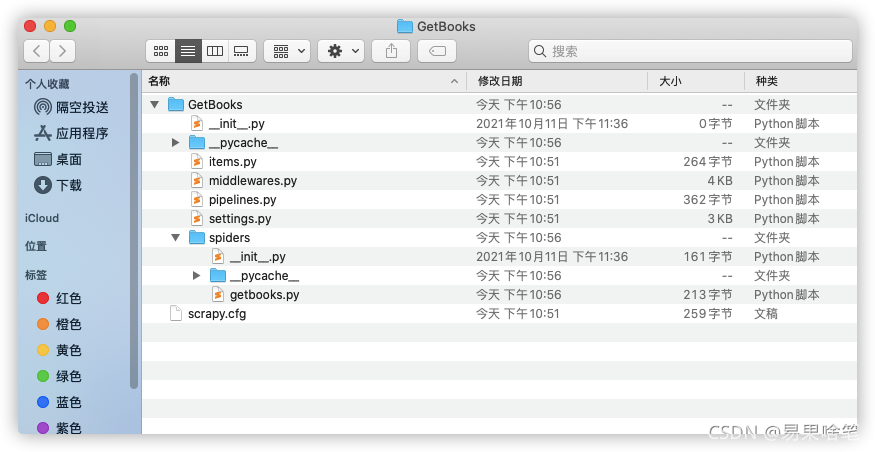
这些文件的具体作用,我们随着学习的深入会一一了解。
我们使用pycharm来打开这个项目,注意这个项目的python解释器中需要导入scrapy包:
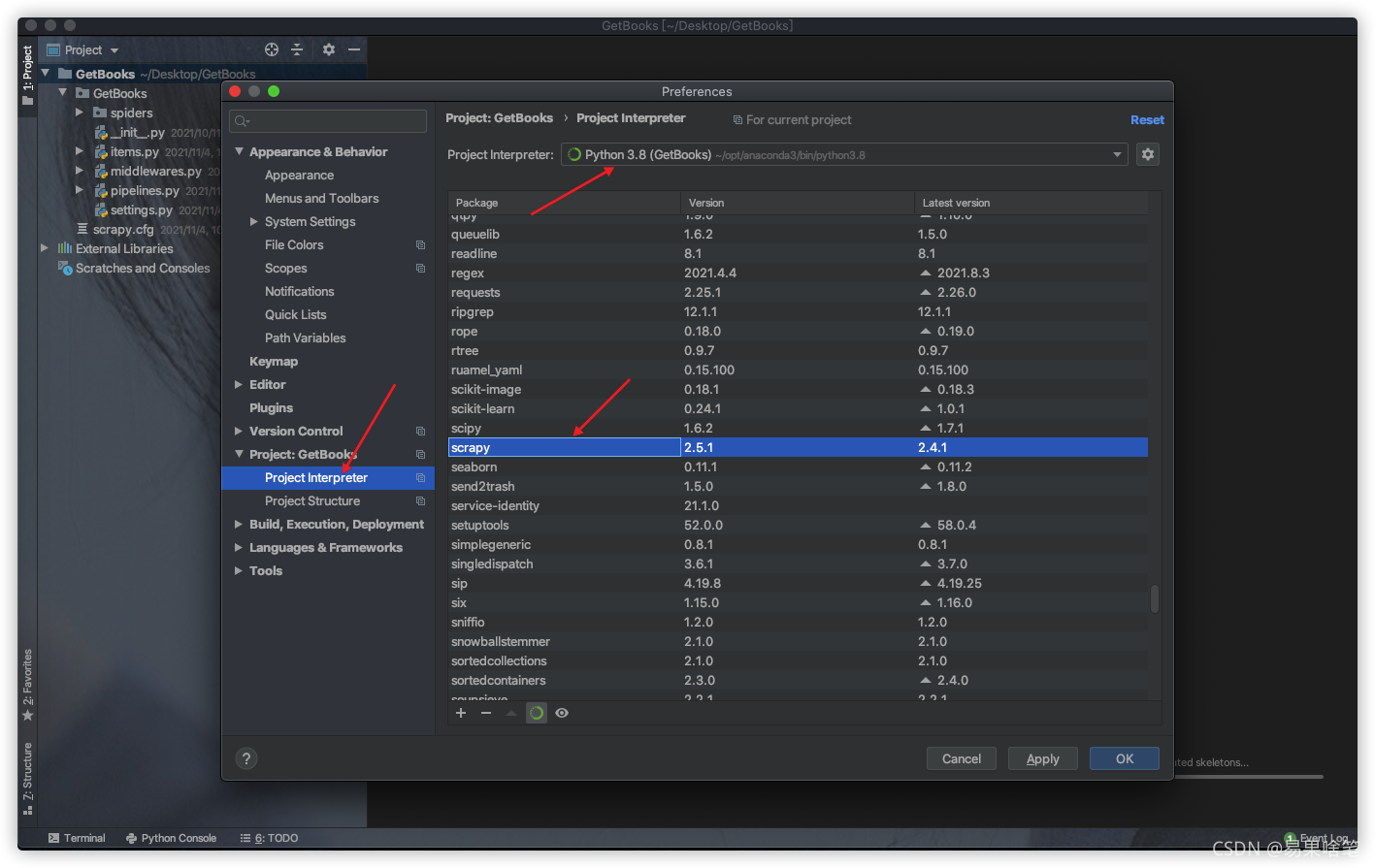
项目结构
设置好环境后,我们来分析这个项目中的文件,可以看到如下这个**getbooks.py**文件:
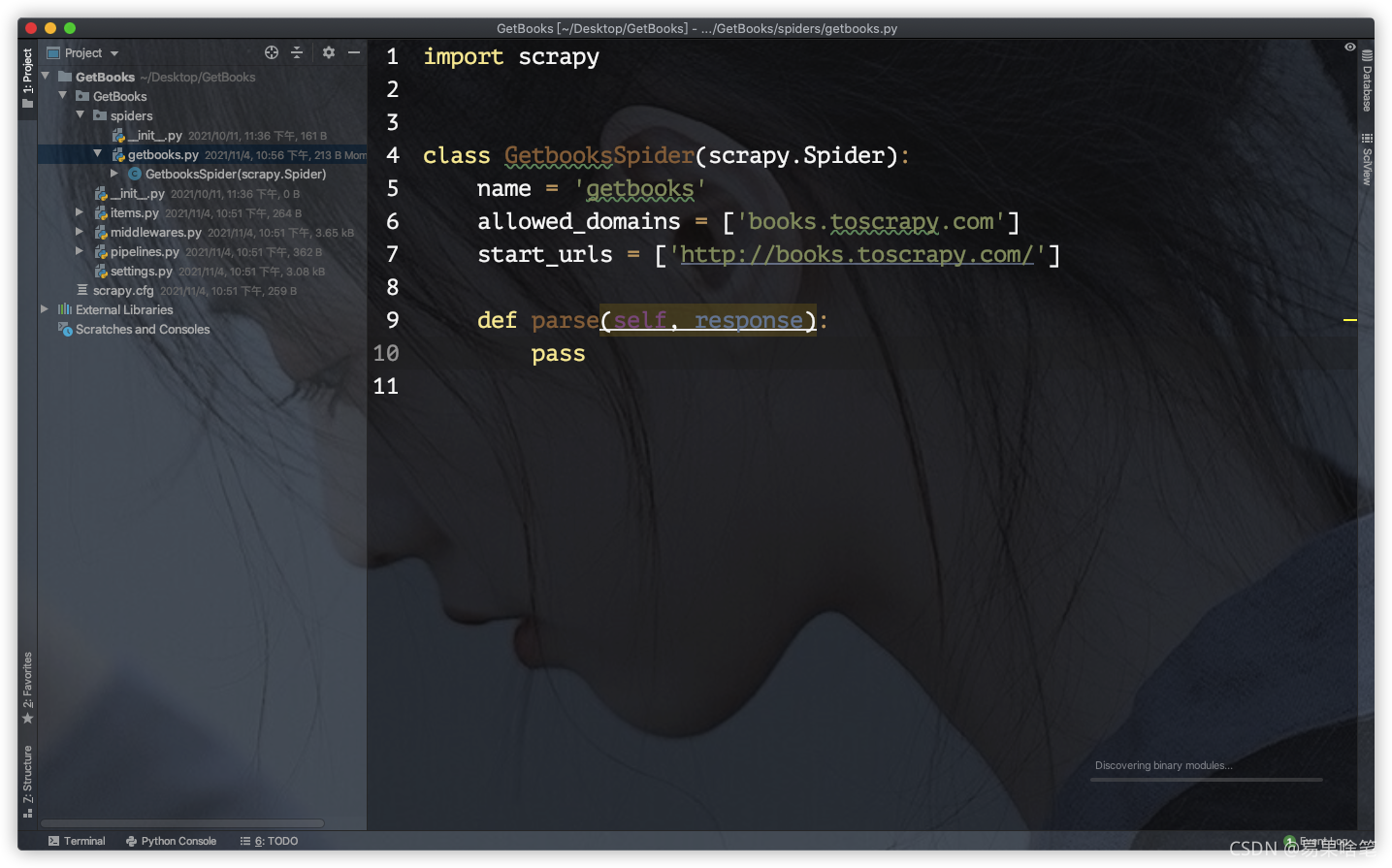
这个文件就是我们编写Spider的核心文件了。基本上我们所有的逻辑代码都在这个文件中。什么逻辑呢?在写任何一个爬虫之前,我们考虑如下三个问题:
- 爬取的时候从哪个或者哪些页面开始爬取呢?
- 对于一个已下载待爬取的页面,提取其中的哪些数据呢?
- 爬取完当前页面后,接下来该爬取哪个或者哪些页面呢?
当回答完上述问题,一个爬虫也就开发出来了。
一般而言,编写一个Spider只需如下四个步骤:
- 继承scrapy.Spider;
- 为Spider取名(爬虫名);
- 设定起始爬取点(网址列表);
- 实现页面解析函数;
我们来分析一下这个核心文件中的代码:
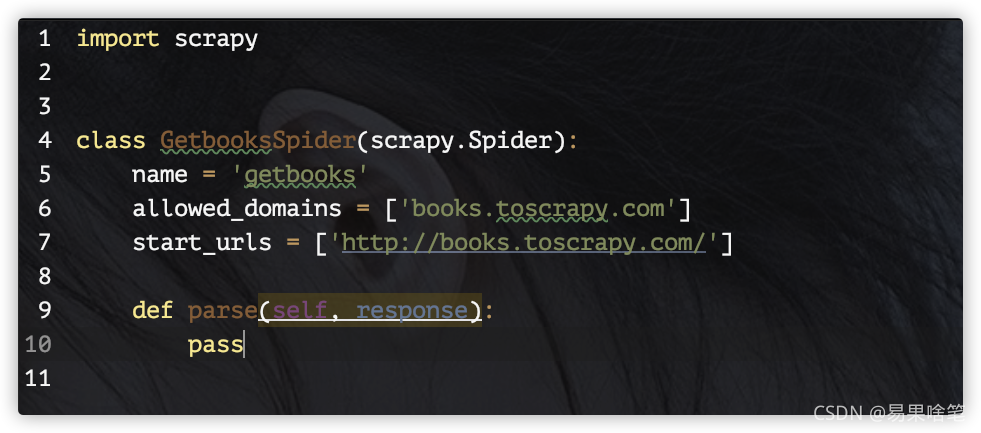 这段代码虽只有10行,但已经囊括了上述的四个步骤,解释如下:
这段代码虽只有10行,但已经囊括了上述的四个步骤,解释如下:
Scrapy框架提供了一个Spider基类,我们编写的Spider只需要继承它即可(代码第四行)- 有时候我们编写的爬虫不止一个,因此,爬虫名的设置便非常重要,
Spider基类有一个name属性,用来指定爬虫名,如代码第五行,设置此爬虫程序的爬虫名为 “getbooks”。(此处的爬虫名在前面使用命令行创建项目的时候就已经指定了,此处为代码自动生成)Spider基类还有一个allowed_domains属性用于设定爬取网站的域名(亦在创建项目的时候指定了),start_urls属性用于指定爬取的起始网页(可以有多个,采用列表存储)。- 页面解析函数名默认为
parse,代码中使用pass占位,需由我们编写。
Scrapy框架流程
简单介绍一下Scrapy框架的爬取流程。
首先,Scrapy引擎根据start_urls中的url地址向对应网页发送一个request下载请求,用于下载该网页,接着该网页所在网站返回一个response对象,并将该对象作为参数传递给页面解析函数parse(),作为该函数的参数,接下来的爬取工作主要在页面解析函数中进行。
值得关注的是,下载该网页所返回的response对象中,包含了这个网页完整的html代码,那么我们如何选择到指定的html标签呢?
css选择器和xpath选择器
Scrapy框架给此response对象添加了两种选择器函数:css选择器和xpath选择器。首先说明,这两种选择器并无优劣之分。一般而言,在语法上,css选择器要比xpath选择器简洁一些,但xpath选择器在功能上更强大一点。而且实际上,当我们调用css选择器函数时,在python内部会使用cssselect库将css表达式翻译成xpath表达式。关于这两种选择器的使用,列举如下:
CSS选择器常用语法
| 表达式 | 作用 | 举例 |
|---|---|---|
| ***** | 选中所有元素 | ***** |
| E | 选中E元素 | p |
| E1,E2 | 选中E1和E2元素 | div,span |
| E1 E2 | 选中E1后代元素中的E2元素 | div p |
| E1>E2 | 选中E1子元素中的E2元素 | div>p |
| E1+E2 | 选中E1兄弟元素中的E2元素 | p+span |
| .classname | 选中属性class的值为classname的元素 | .info |
| #idname | 选中属性id的值为idname的元素 | #main |
| [attr] | 选中包含attr属性的元素 | [href] |
| [attr=value] | 选中包含attr属性且其值为value的元素 | [method=get] |
| E:first-child | 选中E元素,且E元素为其父元素的第一个子元素 | a:first-child |
| E:last-child | 选中E元素,且E元素为其父元素的最后一个子元素 | a:last-child |
| E:empty | 选中没有子元素的E元素 | div:empty |
| E:text | 选中E元素的文本内容 | p:tex |
xpath选择器常用语法
| 表达式 | 作用 | 举例 |
|---|---|---|
| / | 选中文档的根 | / |
| . | 选中当前元素 | . |
| … | 选中父元素 | img/… |
| E | 选中当前元素的子元素中的所有E元素 | ./a |
| //E | 选中根元素的后代元素中的所有E元素 | //a |
| .//E | 选中当前元素的后代元素中的所有E元素 | .//a |
| * | 选中所有子元素 | //div/*/img |
| E/text() | 选中E元素的文本内容 | //div/a/text() |
| @attr | 选中包含attr属性的元素 | //img/@src |
| @* | 选中所有属性的元素 | //img/@* |
编写页面解析函数
依据前面的页面分析,我们来编写页面解析函数:
1 | import scrapy |
response.css()函数和response.xpath()函数均返回一个列表,由符合选择条件的Selector对象组成的列表,均提供 extract函数(获取所有符合条件的html标签),extract_first函数(获取第一个符合条件的html标签)。yield用于提交对应内容给Scrapy引擎。
第三步:运行项目
代码编写完毕后,我们来运行这个项目:
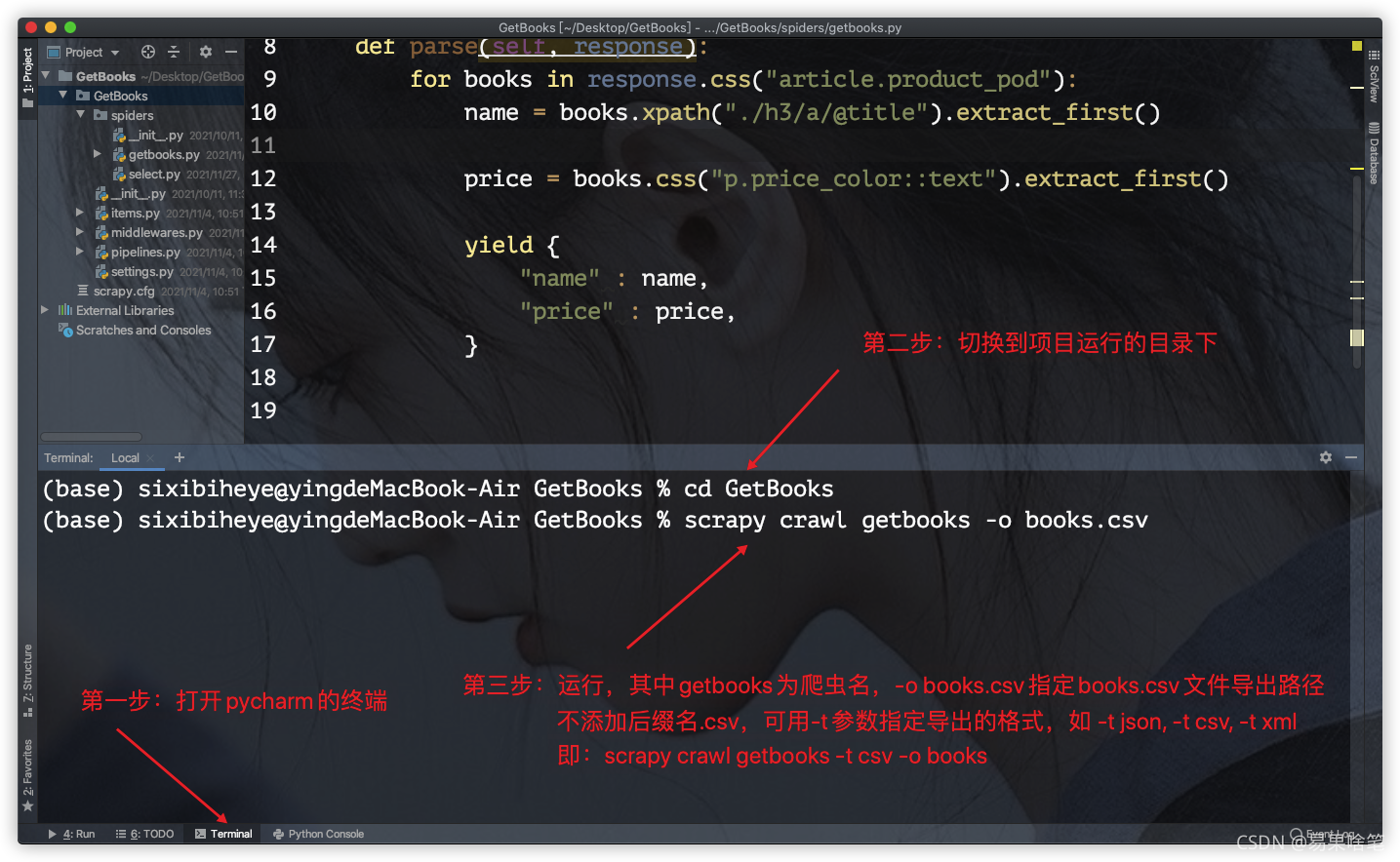
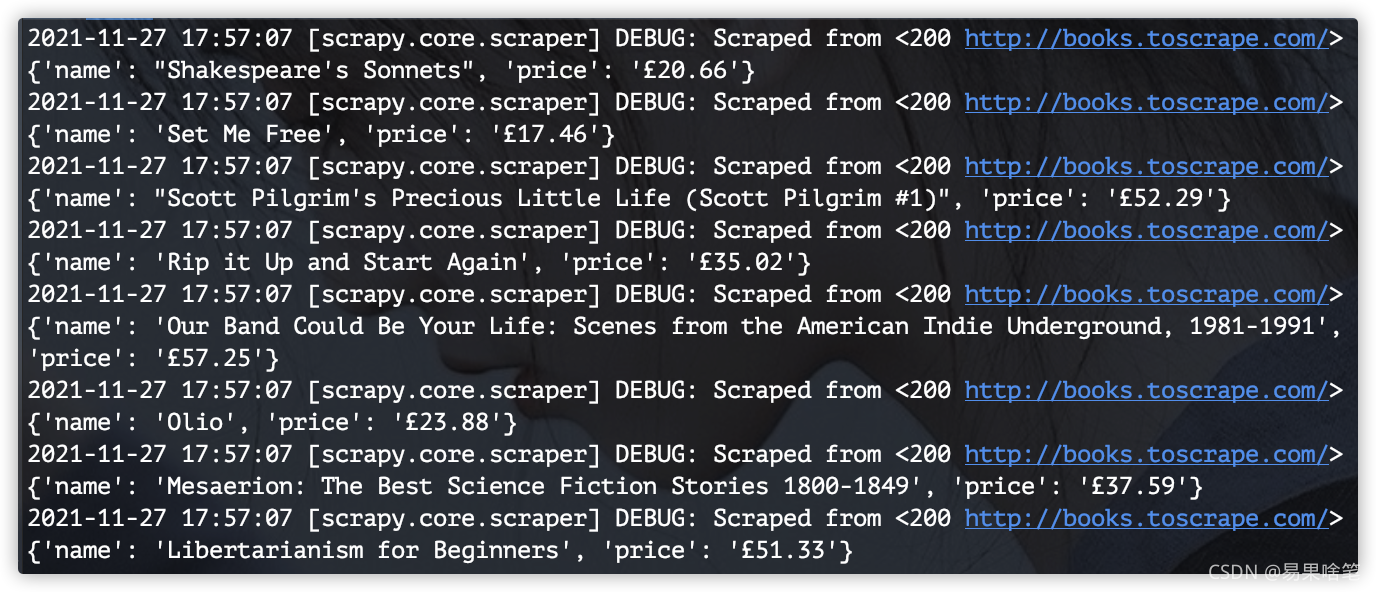
当出现类似如下信息时,即为爬取成功:
运行结束后,在我们指定的目录下,可以看到生成的books.csv文件:
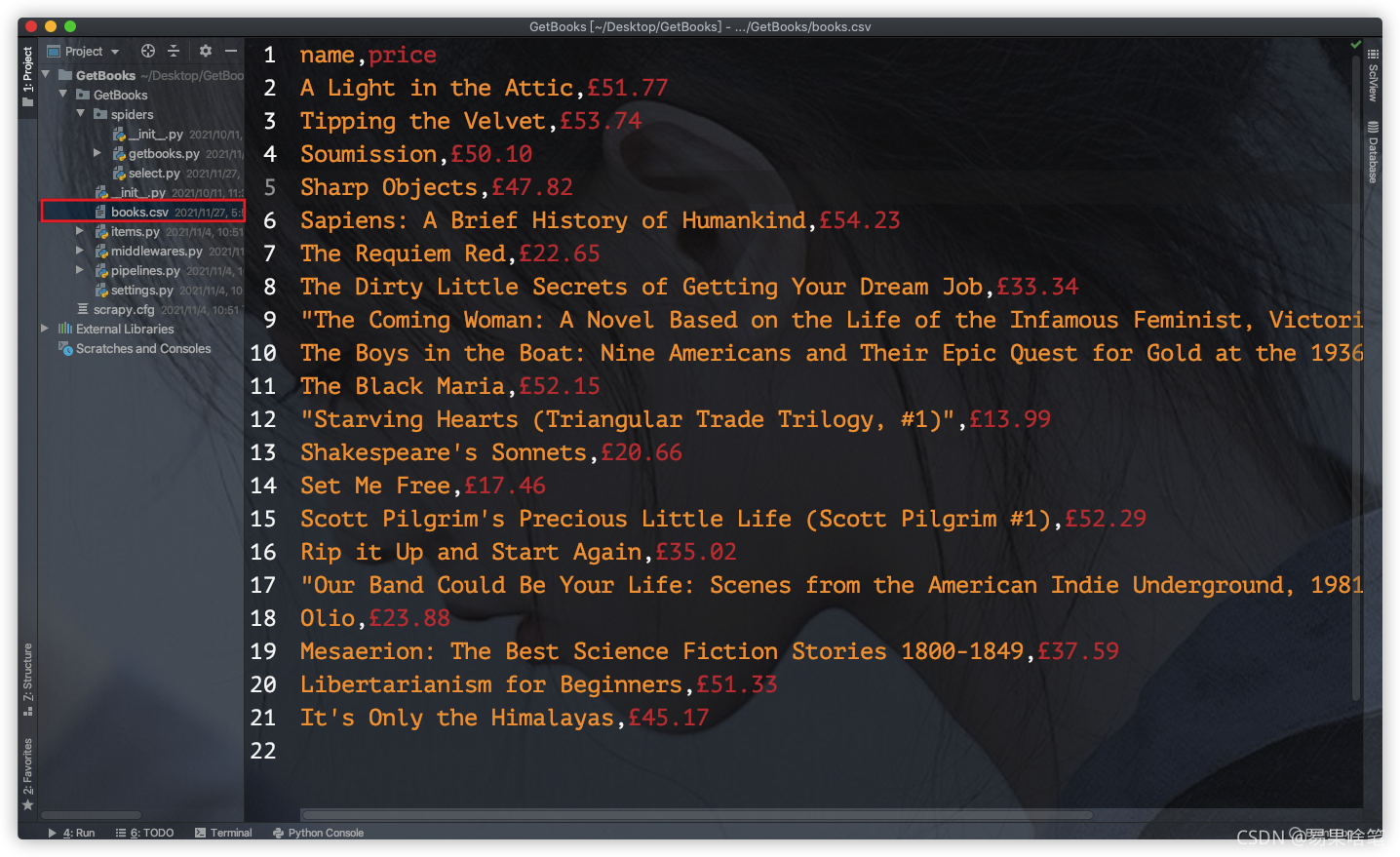
一个简单的爬虫程序就开发出来了。
当然这只是一个最为简单的爬虫,随着接下来的深入学习,我们能够实现一些更为复杂的爬取工作。
