
前言
现在疫情当前,卑微的我只能乖乖的宅在家里敲代码了🙁。之前有朋友让我帮他在网上下载一些图片,那几千张图片手动一个一个下载显然不太实际。所以搬出我们的重量级工具:
人生苦短,我用python
就个人使用体验来说,用python批量下载图片确实要比手动下载快得多,但这一切的前提是建立在你有一定的爬虫基础之上,如果基础不够,就像我刚开始学的那样,折腾了一两个小时还没有手动下载的快。但是,这是每个人都必须要经历的一个过程,谁一开始不是个小白呢?
🤣着实无聊,所以我顺便也把爬取的过程记录了下来。作成此篇。
笔者的专业不是爬虫,所以也用不到什么非常专业的理论技术。只是一些比较简单的库或者框架而已。对于爬虫,就学习生活上的问题而言,我们只需了解 Python+requests+selenium 这三个组合就完全够用了。总结说来,笔者所遇到的爬虫问题,大多可以分为以下三类:
纯Html静态页面
这种页面是一种最为简单的页面。简单来说,纯Html静态页面未使用js渲染,而浏览器一次性渲染得到的纯Html文本,只需简单的xml定位即可获取对应信息,使用Python的requests库即可搞定。
渲染动态页面
页面采用js动态渲染,是部分网站应对爬虫的举措之一。什么是js渲染动态页面呢?简单举个例子,网易云音乐。如果网页允许使用js渲染,则网易云的官网长这个样子:
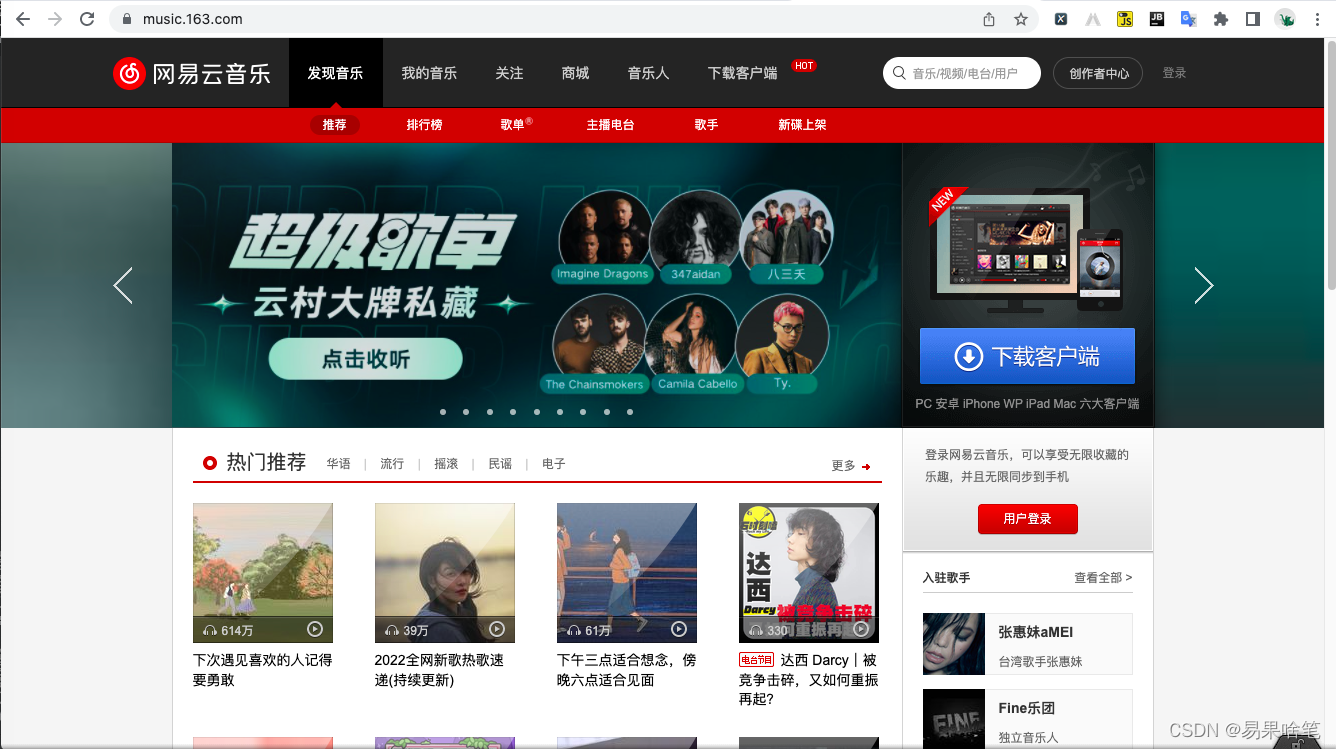
谷歌浏览器提供了一个有用的插件 ----- Toggle JavaScript,使用它可以禁止网页使用js进行渲染,我们来看看禁用js后的网易云页面(注意右上角的按钮):
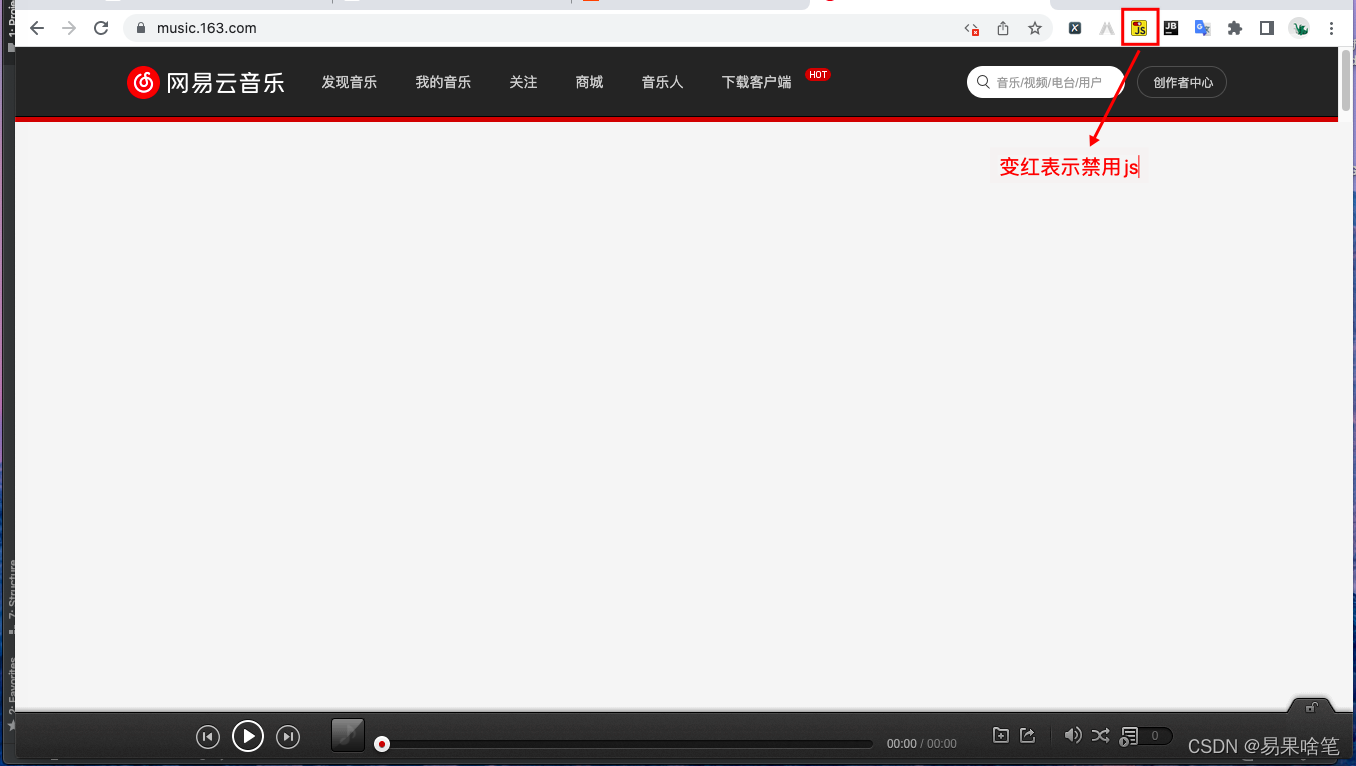
一旦禁用js,你看到的只是其官网上的一些静态Html元素,而往往这些元素对我们没有用处。这说明网页上对我们有用的信息,大多都是通过js实时渲染出来的,因而这类信息的爬取,requests库就无能为力了。
再如,图片类网站,我们的鼠标不断往下滑的时候,图片也慢慢地增加并显示,这种页面,显然不可能是静态的,也无法用requests库爬取。
所谓魔高一尺道高一丈,自动化测试工具 selenium可以帮助我们解决这个问题。当然这个工具的主要应用领域不在爬虫,但我们仍然可以使用它来帮助我们渲染js页面。
Ajax请求数据
学过前端的小伙伴们应该很清楚,前端页面上的数据,大多需要从后端服务器上获取,一般使用Ajax请求,而且,这些通过Ajax请求从后端获得的数据往往正是我们所需要的。
就如我之前写的批量爬取四六级成绩文章,里面的爬虫程序其实非常简单 ,就访问了一个接口而已:
http://cachecloud.neea.cn/api/latest/results/cet?e=CET_202112_DANGCI&km=2&xm=罗颖&no=4311...&v=
访问类似这种的接口,其服务器的响应大多是以json串或者xml数据的格式,其中就包含着我们想要的数据。
这种接口一般是网站提供的,由于前端页面的数据填充展示过程中需要用到这个接口返回的数据,因此这个接口往往都是开放的,我们可以访问,爬虫程序当然也可以(部分网站为了反爬,会混淆接口参数) 。
所以,这种类型的爬虫程序,难点不在于代码编写(使用requests库即可实现),而在于如何找到这种接口,即分析页面的过程。
当然,在实际的爬取过程中,也许会同时用到上面的两种或者三种,这需要我们灵活运用。
爬取百度图片
下面开始我们的正片…今天来爬取百度图片。百度输入“图片” :
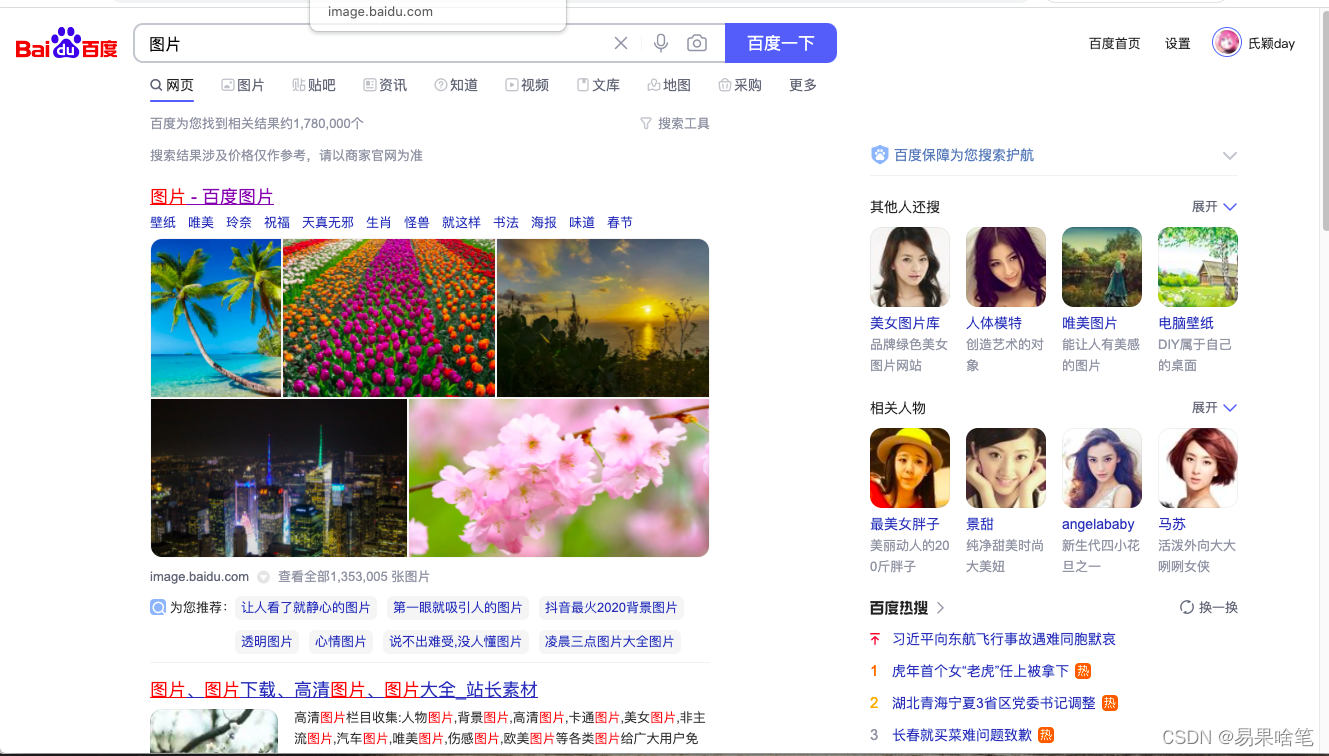
进入第一个搜索结果,图片尺寸选择特大尺寸(注意图片尺寸那里,不同的尺寸选择得到的url地址不同,说明是不同页面):
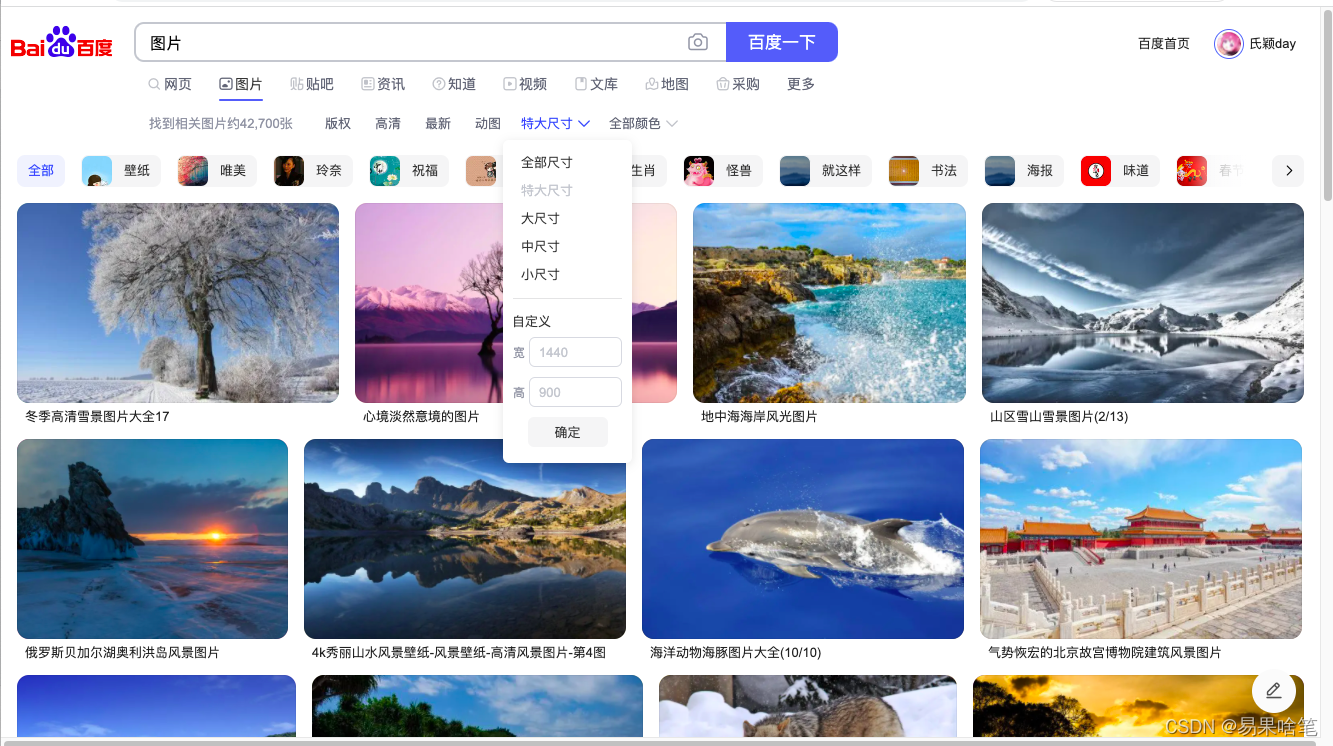
我们针对百度图片中的“特大尺寸”的图片进行爬取 。单击搜索地址栏,可以看到此页面完整的url地址:
这就是我们待会要爬取的入口页面地址。
selenium安装
之前提到过,这种图片页面往下滑会不断的更新出图片,我们猜测这应该是个动态页面。事实上,如果禁用js,你会发现页面直接跳转到了百度图片网站的首页,这说明,刚看到的整个页面都是由js渲染出来的…所以requests库就无能为力了…需要用到selenium。
关于selenium的安装和使用,本文就不再介绍了。网上的教程讲的都非常详细…比如这位大佬:
selenium用法详解【从入门到实战】【Python爬虫】【4万字】
selenium是最广泛使用的开源 Web UI(用户界面)自动化测试套件之一。Selenium 支持的语言包括C#,Java,Perl,PHP,Python 和 Ruby。目前,Selenium Web 驱动程序最受 Python 和 C#欢迎。
依据此博文的步骤,安装selenium驱动后,再下载python的selenium支持库:
pip install selenium
安装完成之后,就可以开始使用了。
分析页面
分析页面除了一些基本的工具和技巧之外呢,大部分都是熟能生巧,当爬的多了,自然就能猜到大概应该怎么去分析。
比如,图片的这种展示,有很多张,我们最为直观的猜测便是,一张图片放在一个 li 标签里。因此我们在分析网页的时候,会更加关注 li 标签。
再比如,平台上的评论数据一般都会提供一个接口供访问,找到接口就已经解决一半的问题了。
利用谷歌浏览器自带的开发者工具(按F12弹出,对网页的分析,基本上都需要这个),我们随便找一张图片,右键点击“检查”,就能迅速定位到图片元素所在的Html标签:
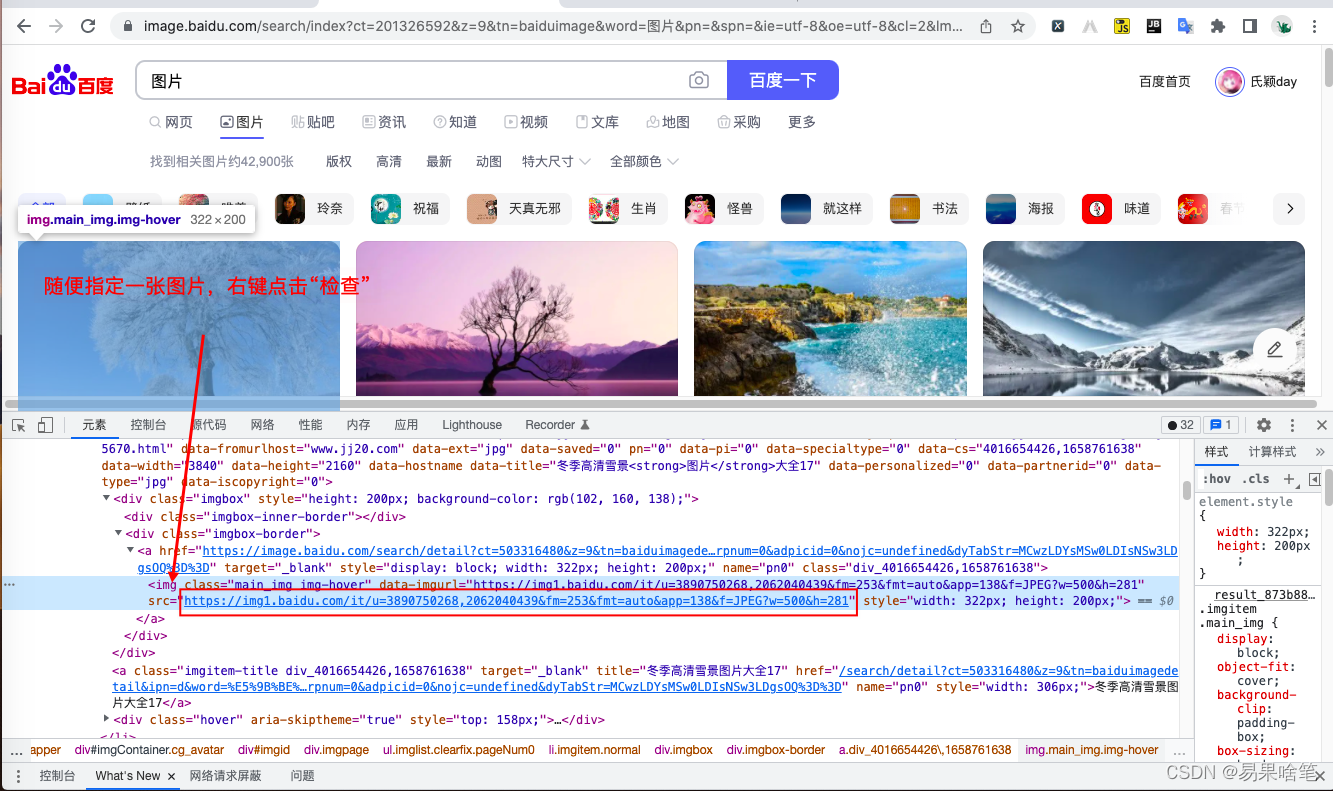
很容易找到这张图片的url地址(img标签的src属性) ,同时,每张图片下面还有一段文字说明,我们就用这段文字来命名这张图片。
这样看来,我们还需要爬取图片下面的那段文字,可以使用图片同样的方法,右键文字段处点击“检查”,定位到文字元素所在的Html标签,不过那段文字在Html文本中出现的地方有很多,我们随便取一个,比如:
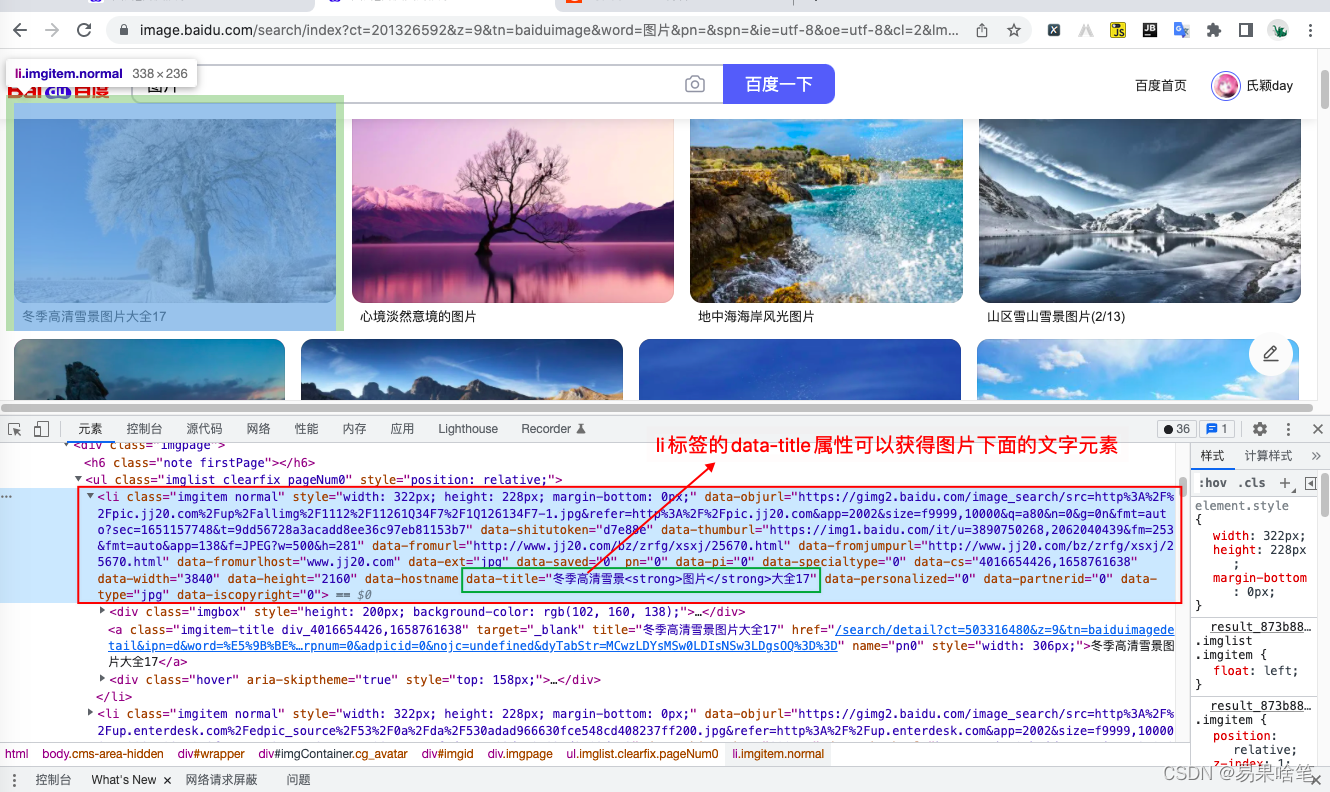
这段Html源码印证了我们之前的猜测 ------- 一张图片放在一个 li 标签里。而且不止图片,它下面的文字段也包含在对应的 li 标签里。
这样,我们对要爬取的内容就有了一个直观的了解。
XPath Helper
一般而言,Html标签元素的定位使用的大多是xpath或者css表达式,这是爬虫最为基础的内容,如果小伙伴们还不太清楚的话,可以先去学一学基本语法,再来看本章内容。
谷歌浏览器提供了一个插件 ------ XPath Helper,它允许我们在浏览器上的某页面直接执行xpath语法定位对应元素并提供结果展示。因此大多数情况下,我们都会使用 XPath Helper来验证我们的猜想,比如上述图片的url地址的定位,xpath语法应该这样写:
//img[@class="main_img img-hover"]/@src
可以看到浏览器返回的结果:
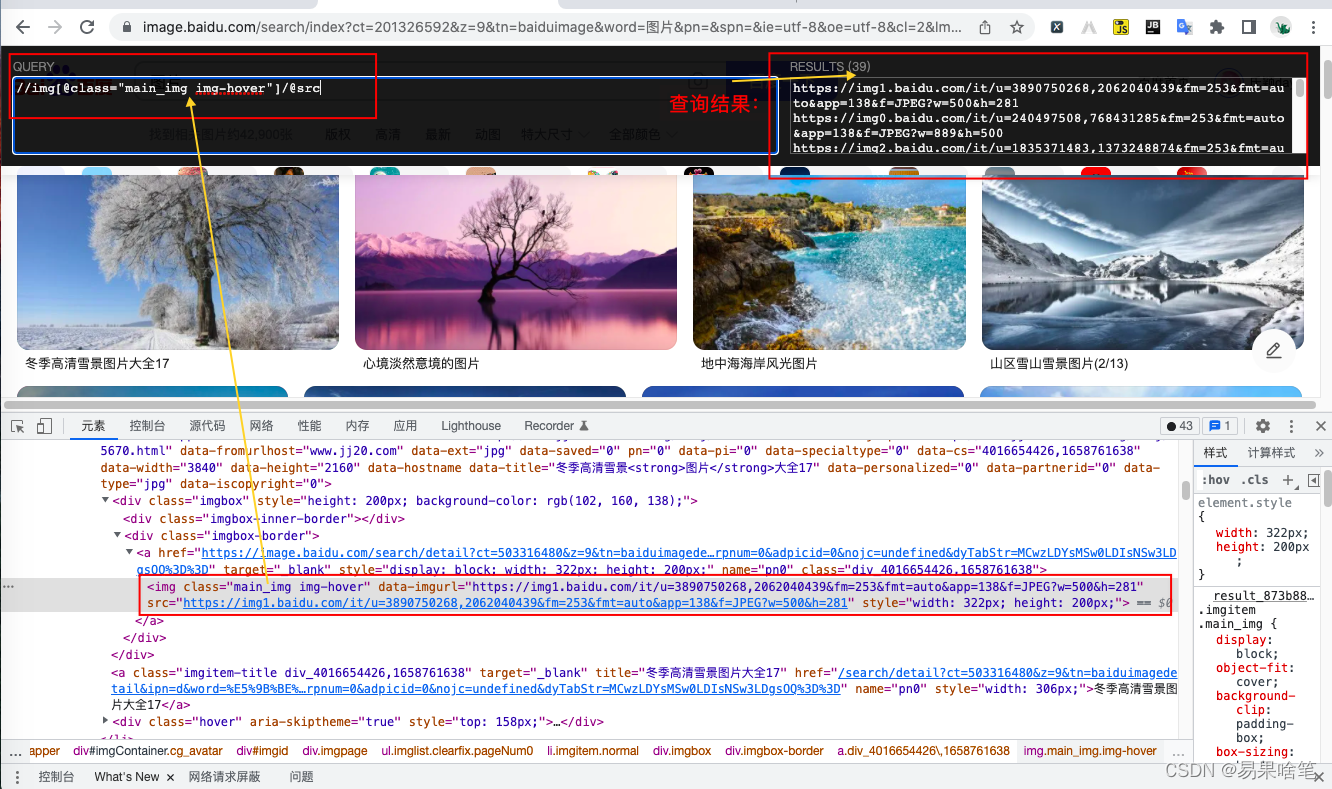
可以看到,我们成功的获取到了所有39张图片的url地址,这说明我们的xpath表达式符合要求。
再来思考一个问题,为什么只有39张呢?
之前说过,这是个动态页面,我们在鼠标往下滑动之前,浏览器使用js仅渲染了部分图片,此时渲染页面得到的Html源码中只有39个 li 标签,因此xpath表达式就只找到了39个url地址,那我们想要更多的图片url地址怎么办呢?
简单,让鼠标往下滑就行了。我们来验证我们的想法:
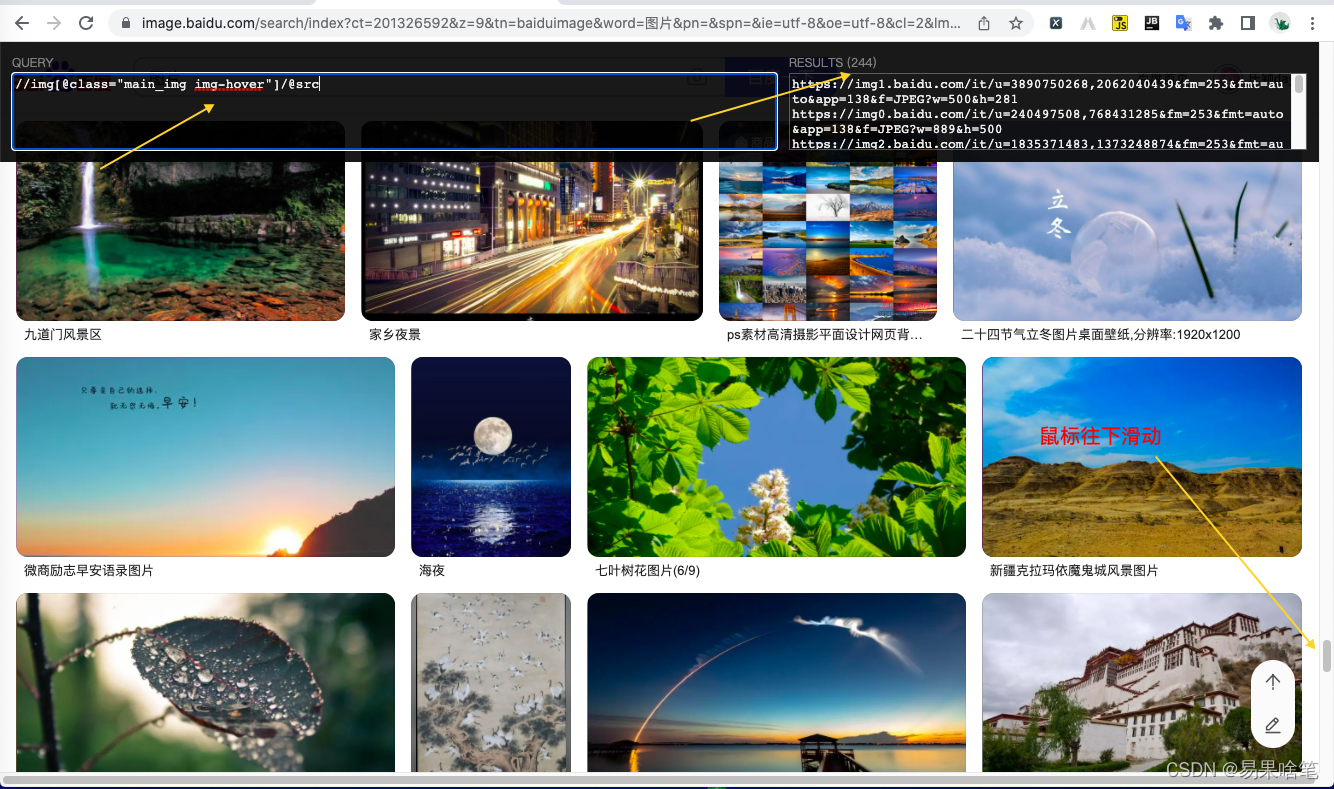
显然,往下滑之后,同一个xpath表达式找到了更多的url地址,有了更多的 li 标签。这也同时说明了这个页面的Html文本是使用js实时渲染出来的。
代码编写
有了以上的分析,结合Python+requests+selenium ,我们就可以开始爬取代码的编写了:
首先导入相关的库:
1 | import re |
re库用于正则提取;time库用于强制休眠,防止爬取过快ip被封; os库操作文件及文件夹,用于保存图片;requests,selenium用于爬取数据。基本上,爬虫所需要的所有库都在这了。
在当前目录下建一个images文件夹,用于存放下载的图片(当然也可以自定义下载路径):
1 | if not os.path.exists('images'): |
接着初始化 selenium:
1 | # options = Options() |
如果不想自动打开谷歌浏览器,可将注释段代码替换第一行代码。
接着我们来思考一个问题,如何实现鼠标下滑的操作呢?selenium的自动化测试功能,其webdriver类提供了一个**execute_script()**方法可以用于执行js脚本,而在JavaScript中,要实现下滑操作太容易了,我们定义一个函数:
1 | def scroll(driver, px='document.body.scrollHeight'): |
函数很简单,在此就不多做解释了。现在,我们在上述爬取代码中调用该函数:
1 | scroll(driver, '10000') |
我们让鼠标下滑,让页面往下翻10000像素, 如果你想下载更多的图片,调整这个数值即可。此外需要注意的是,此处一定需要等待几秒后再进行之后的爬取工作,由于网络缓慢等原因,下滑后页面的Html还没有完全渲染出来,这时如果立即进行xpath表达式爬取就会漏掉部分还未被渲染出来的li标签,导致数据信息丢失。
接着来爬取图片的url地址和文字段说明。
爬取过程中总会出现各种各样的错误和不足。这需要我们慢慢修正我们的代码。比如url地址,使用xpath表达式
//img[@class="main_img img-hover"]/@src
提取到的不一定都是有效的url格式,比如实际提取过程中,匹配到了下述内容:
data:image/jpeg;base64,/9j/4AAQSkZJRgABAQEASABIAAD/2wBDAAYEBQYFBAYGBQYHBwYIChAKCgkJChQODwwQFxQYGBcUFhYaHSUfGhsjHBYWICwgIyYnKSopGR8tMC0oMCUoKSj/2wBDAQcHBwoIChMKChMoGhYaKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCj/wAARCAFLAfQDASIAAhEBAxEB/8QAHAAAAgIDAQEAAAAAAAAAAAAABAUDBgACBwEI/8
这显然不是我们想要的url格式,因此在获取到某个url地址内容后,我们需要做一个判断,最简单的判断方式---------判断这玩意是不是以“http“开头的,我们使用re模块:
1 | if re.match(r'^(http)', img.get_attribute('src')): |
好了,现在可以将爬取到的url地址使用requests库进行下载保存了:
1 | # li标签作为根标签,使用xpath表达式 |
完整代码
下面是完整代码:
1 | import re |
运行程序
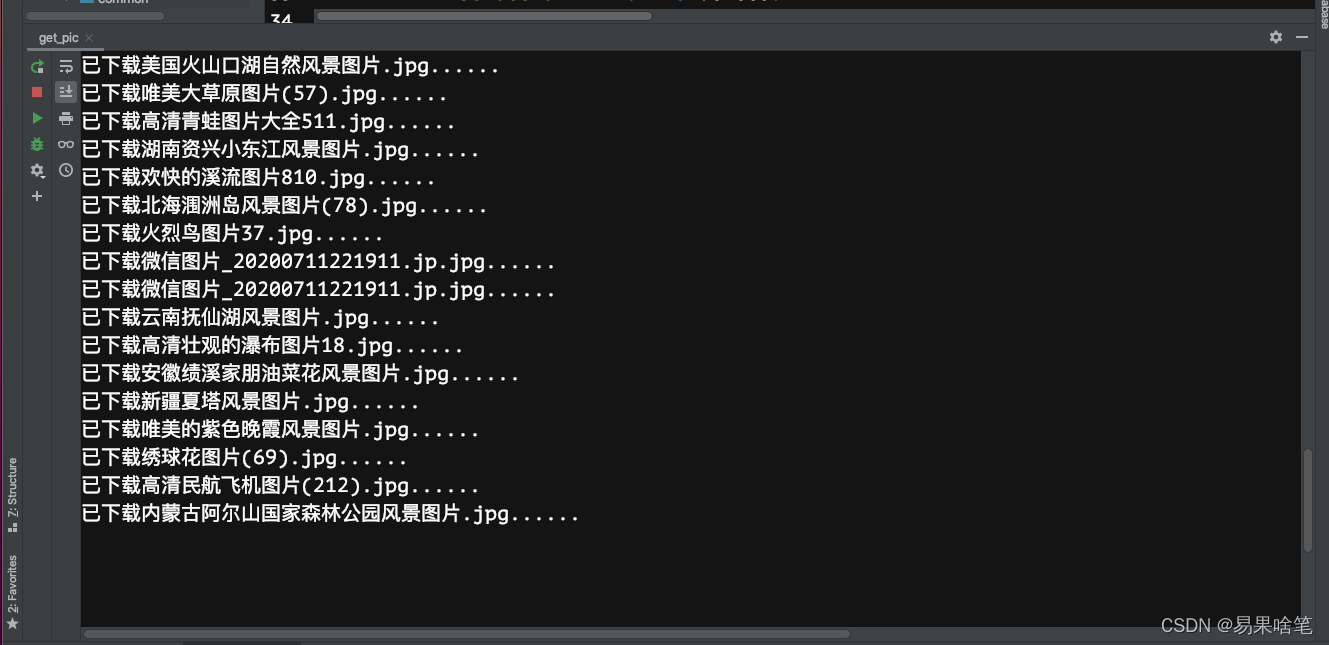
结束后,在当前目录下生成images文件夹,里面存着爬取到的图片:
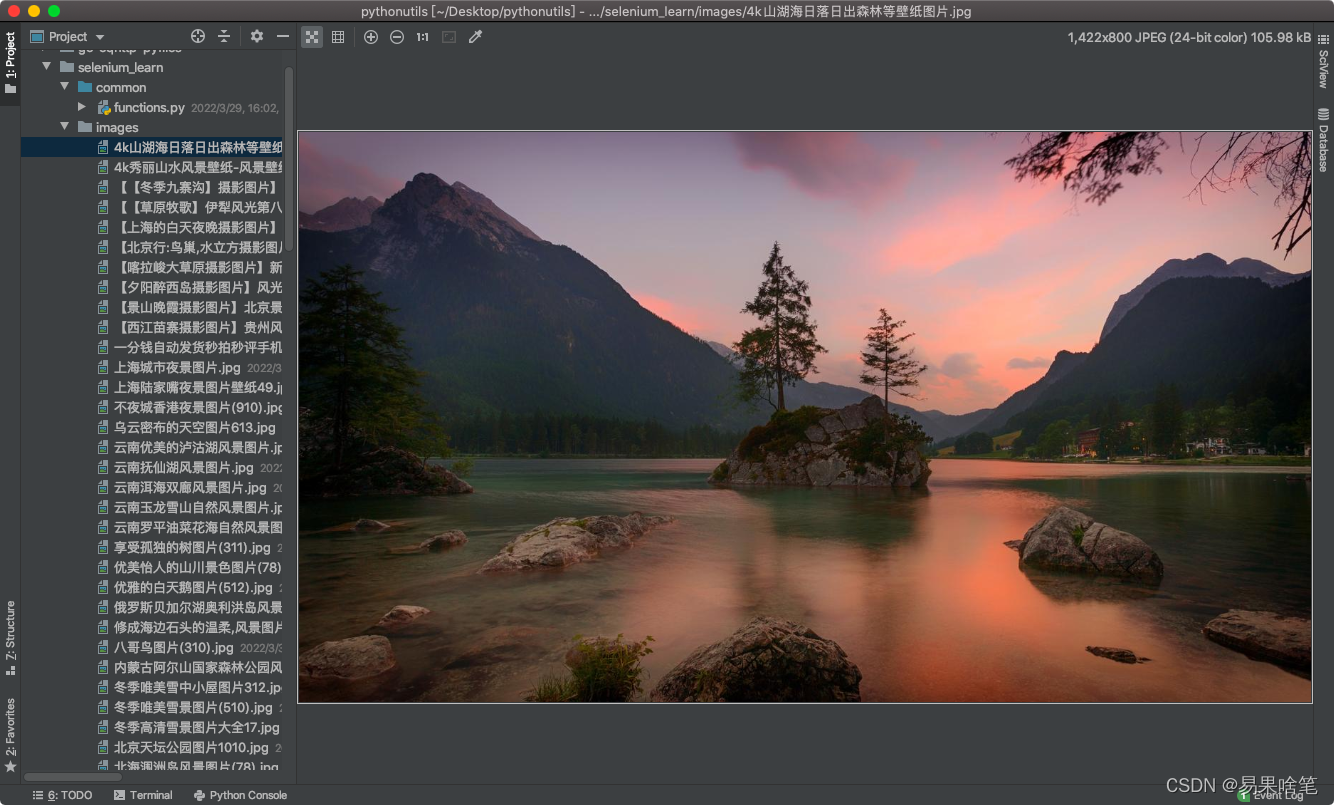
过程感觉挺长的,但是大多时间还是花在思考上,代码本身编写不难,难在整个分析过程。基本上使用上述爬取流程,可以爬取当下90%以上的网站图片了。
