前言
全网都在追的2022年新剧《开端》🤣…不会有人看了几十分钟的弹幕吧…我想了想,看弹幕不太方便,所以干脆爬下来…
网页分析
在b站,很容易找到弹幕的接口:
https://api.bilibili.com/x/v1/dm/list.so?oid={oid/cid}
这个接口需要一个参数oid,这其实是b站的每个视频的独一无二的编号,怎么搞到这个编号呢?
我们来瞧瞧b站随便一个视频的url地址: 
其实,b站每个视频的URL中都有一串bvid字符编号,比如BV1wq4y1C785,通过这个bvid编号,我们可以轻松获得视频对应的oid编号,这是因为…b站又给我们提供了一个另一个接口:
https://api.bilibili.com/x/player/pagelist?bvid=BV1wq4y1C785
如上,我们将这串字符输进去,在浏览器中输入回车,看到以下结果:
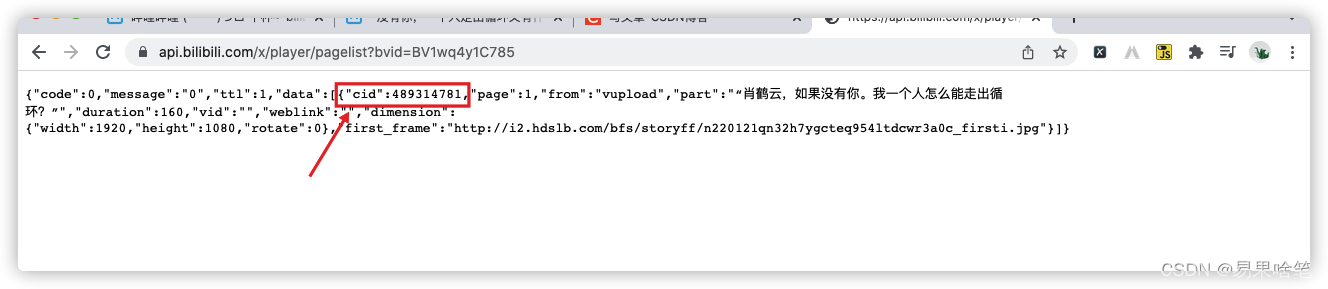 可以看到
可以看到b站服务器返回的response是一个json格式的文本,里面有一个键cid,它的值就是我们想要的cid编号。将此编号输入前述的弹幕接口地址中:
https://api.bilibili.com/x/v1/dm/list.so?oid=489314781
浏览器打开,可以看到如下结果:
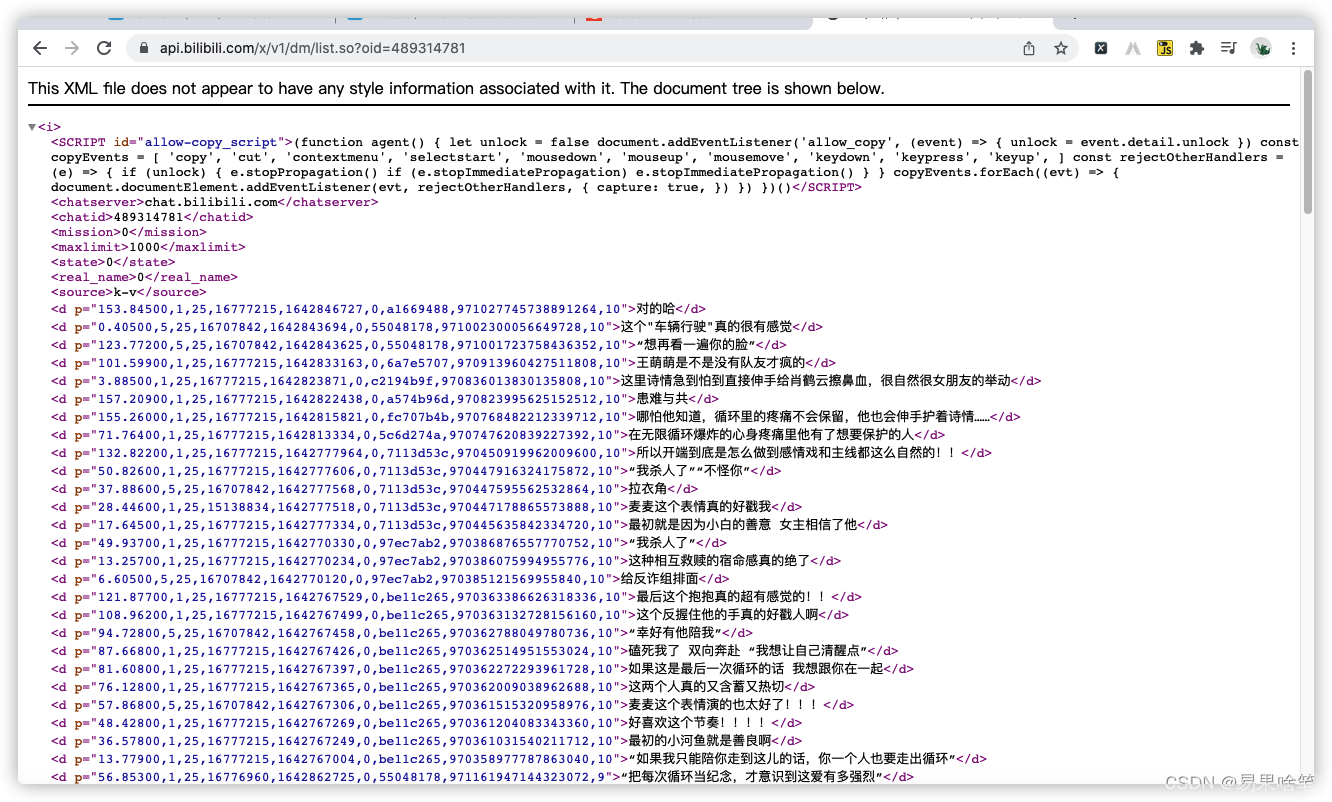
由此看出,咱可爱的b站把弹幕集中放在了一个xml文件中…从这个文件中提取弹幕不算太难,可以使用正则提取。此外, 我们关注的还有弹幕发布的时间,其实xml文件中有,只不过不太明显…
1642863060
这是一个用Unix时间戳表示的时间,简单来说就是从1970年1月1日(UTC/GMT的午夜)开始所经过的秒数(不考虑闰秒),至于如何计算,就交给Python吧。
代码编写
准备工作完毕,我们就开始爬了,这个爬虫非常容易,使用requests库即可完成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| import re
import time
import requests
import json
def get_comments(bvid):
"""
通过视频的bvid获得视频的cid
输入:视频的bvid
输出:弹幕发布时间及弹幕内容
"""
url = 'https://api.bilibili.com/x/player/pagelist?bvid=%s' % bvid
res = requests.get(url)
cid = res.json()['data'][0]['cid']
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=%d' % cid
res = requests.get(url)
res.encoding = 'utf-8'
text = res.text
result = []
comments = re.findall('<d p="(.*?)">(.*?)</d>', text)
for comment in comments:
item = {}
comment_date = int(comment[0].split(',')[4])
item['评论时间'] = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(comment_date))
item['弹幕内容'] = comment[1]
result.append(item)
comments_json = json.dumps(result, indent=0, ensure_ascii=False)
return comments_json
if __name__ == '__main__':
comments = get_comments("BV1y34y1B7q9")
print(comments)
|
运行程序
跑一下,结果如下(部分):

使用scrapy实现
习惯使用scrapy框架的小伙伴们,也可以使用scrapy实现(当然有点大材小用了):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| import time
import scrapy
import re
class KaiduanSpider(scrapy.Spider):
name = 'kaiduan'
allowed_domains = ['api.bilibili.com']
start_urls = [
'https://api.bilibili.com/x/player/pagelist?bvid=BV1wq4y1C785',
]
def parse(self, response):
cid = re.findall('"cid":(d+)', response.body.decode())[0]
yield scrapy.Request(
'https://api.bilibili.com/x/v1/dm/list.so?oid=' + cid,
callback=self.parse_comments
)
def parse_comments(self, response):
"""
解析视频弹幕
输入:视频弹幕的原数据
输出:弹幕的解析结果
"""
comments = re.findall('<d p="(.*?)">(.*?)</d>', response.text)
for comment in comments:
item = {}
comment_date = int(comment[0].split(',')[4])
item['评论时间'] = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(comment_date))
item['弹幕内容'] = comment[1]
yield item
|
终端运行程序,输入命令 scrapy crawl kaiduan -o comments.csv回车,运行完之后,得到如下csv文件: 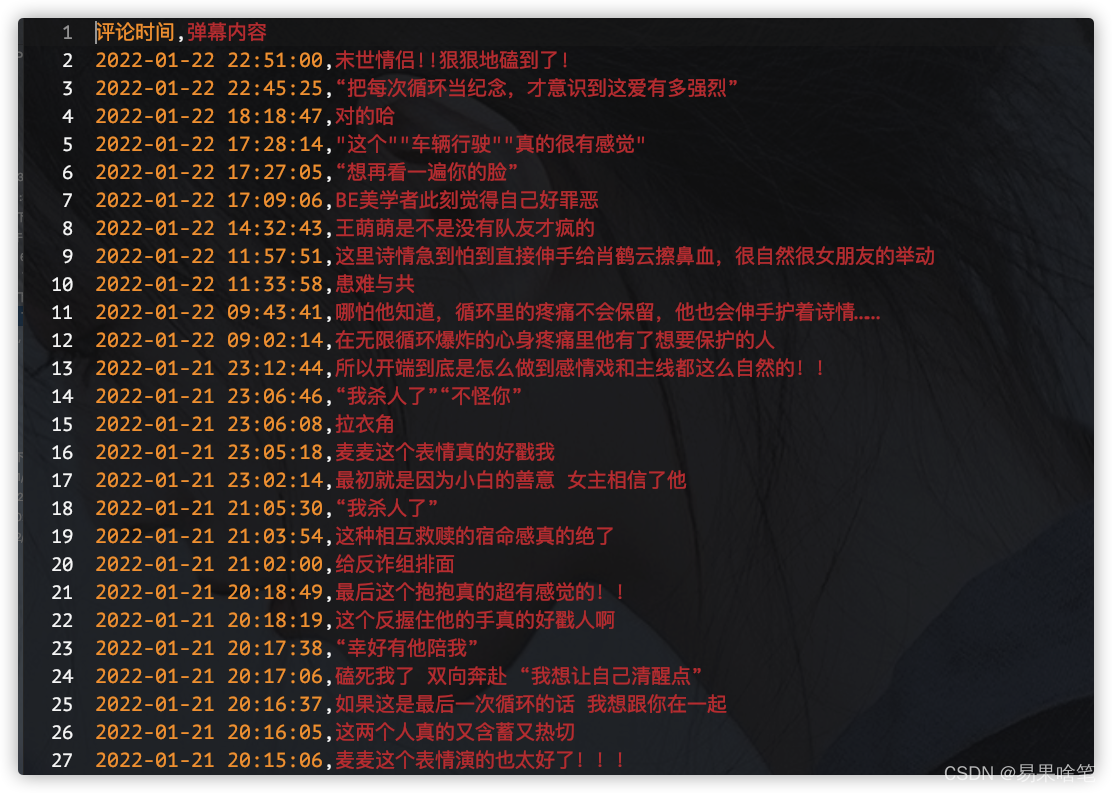 哈哈,是不是挺有乐趣的呢?
哈哈,是不是挺有乐趣的呢?

